Abstract Style: Modular Monolith (a.k.a. 'Vertical Slice Architecture')

When many developers these days are asked “Which is better: Monolith or Microservices?” The answer is often a resounding ‘Microservices!’ The term monolith has become a pejorative; a veritable four-letter word in some software architecture circles. The folk-wisdom criticisms are not entirely undeserved, after all there are a lot of bad monoliths out there; unmaintainable, untestable, brittle to the point of personifying a Jenga tower of code. Yes, the microservices pattern offers many strengths. Yes, the layered monolith carries many weaknesses. However, that’s not the end of the story. As we have learned so far in this series, capabilities like testability, maintainability, evolvability, etc. don’t originate from deployment granularity but instead emerge from architectural constraints.
What might the humble monolith look like if an architect applied some of the constraints that give microservices their magic? Meet the Modular Monolith.
This post is part of a series on Tailor-Made Software Architecture, a set of concepts, tools, models, and practices to improve fit and reduce uncertainty in the field of software architecture. Concepts are introduced sequentially and build upon one another. Think of this series as a serially published leanpub architecture book. If you find these ideas useful and want to dive deeper, join me for Next Level Software Architecture Training in Santa Clara, CA March 4-6th for an immersive, live, interactive, hands-on three-day software architecture masterclass.
Introducing the Modular Monolith
The modular monolith is not a new concept. In reality, it has been widely documented and described in architecture literature in recent years. Consequently, in this work, it is just another abstract architectural style that forms the foundation for a Tailor-Made architecture (to be extended and modified by additional constraints creating the optimal architectural style for a project). The Modular Monolith begins with an emphasis on the idea of modular programming:
“Modular programming is a software design technique that emphasizes separating the functionality of a program into independent, interchangeable modules, such that each contains everything necessary to execute only one aspect of the desired functionality. A module interface expresses the elements that are provided and required by the module. The elements defined in the interface are detectable by other modules. The implementation contains the working code that corresponds to the elements declared in the interface.”
The key takeaways are:
- Modules must be independent and interchangeable
- Modules must be self-contained
- Modules must have a defined interface
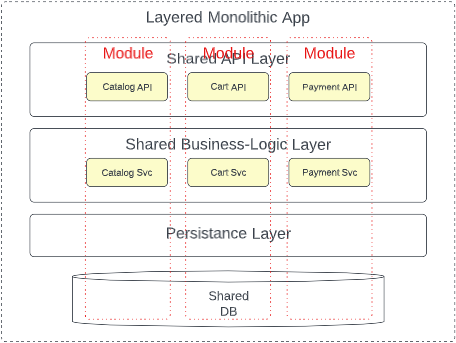
Like many words in our industry, the term “module” is overloaded. Arguably the presentation layer or business logic layer of the classic layered monolith could be considered modules. The modular monolith becomes opinionated on what constitutes a module, adopting a key idea from microservices; domain partitioning.
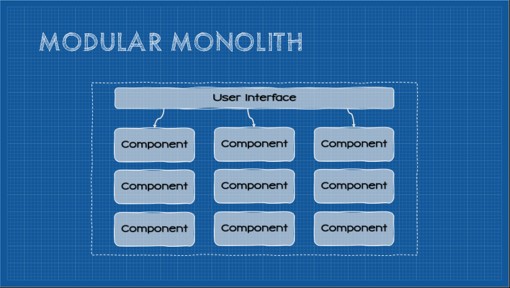
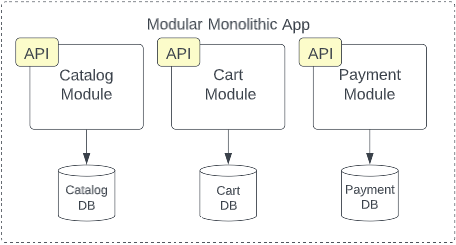
Each module in a modular monolith wholly represents a specific sub-domain or bounded context in the system. These modules encapsulate all functionality necessary to satisfy that given subdomain, exposing only a uniform public interface. The “host” application can interact with that interface but everything else–ideally including the module’s data–is completely hidden from the rest of the application. Essentially the modular monolith creates vertical slices of the monolithic application with boundaries as rigid as those found in microservices.
In essence, each module in a modular monolith roughly corresponds to a microservice. It is a separate package or assembly encapsulating everything necessary to deliver that particular slice of functionality. By adopting the same modularity and encapsulation of the microservices architecture, evolvability, testability, modularity, reliability, and even deployability are improved. By virtue of retaining the monolithic build artifact constraint, the improved cost and simplicity of the monolith is retained. Of course, the trade-off of keeping these modules within the single build artifact and deployment unit is that elasticity, scalability, and fault-tolerance remain similar to those of the layered monolith, or only improve marginally. Likewise, another trade-off is the cost and complexity of domain-driven design and potentially disruptive org changes.
For this abstract definition of the Modular Monolith architecture pattern, the core constraints are as follows:
- Monolithic Build Artifact
- Monolithic Deployment Granularity
- Domain Partitioning
- Separation of Concerns
- Partitioned Shared Database
In the following sections, we’ll examine each constraint and how it elicits certain capabilities while weakening others.
Constraint: Monolithic Build Artifact
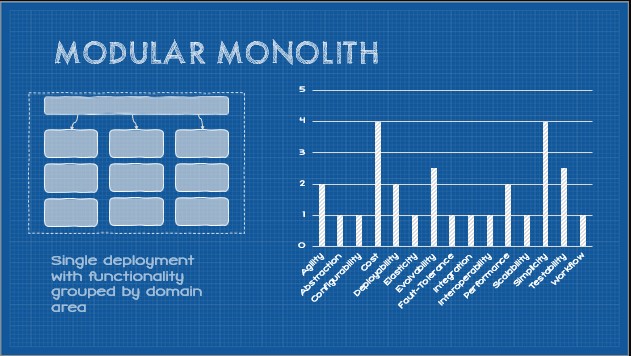
As the title “monolith” (mono - single, lith - stone) suggests, the system is compiled into a single binary artifact. This constraint, like every constraint we will introduce in this series, introduces a set of trade-offs. Let’s start by looking at capabilities that are induced by this constraint.

Simplicity (+2)
If an entire system resides within a single binary, we avoid the challenges that distributed systems face. These types of systems avoid an entire category of complexity that distributed systems introduce. The challenges that distributed systems introduce are best exemplified by the fallacies of distributed computing. In summary, the fallacies are:
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn’t change
- Transport cost is zero
- The network is homogeneous
Basically, the fallacies describe the complexities that emerge when a system becomes distributed. In short, there is a lot less that developers have to worry about with a monolith.
In addition, the build process is generally much simpler. It can be as simple as performing a build in an IDE.
It is generally easier to get started building a monolithic app. We can begin to write code that creates user value without too much thought.
Working in the monolithic codebase is also generally simpler. The entire codebase can be indexed by an IDE providing useful intellisense, there is direct visibility into every part of the system, and since everything is in a single codebase, coordinating changes can be performed in a single commit.
Administration of a single app is also radically simplified. There is much less to monitor or manage.
Performance (+2)
As implied by the fallacies of distributed computing, one unexpected consequence of distributed architectures is some performance penalty incurred through network latency and bandwidth. In memory calls are, thus, faster than network calls. That said, the potential benefits are limited by the available hardware to a given application (even when writing multi-threaded, high-performance code). Resources are shared and are difficult to scale out (as we can with other distributed patterns).
Cost (+1)
A related consequence of axis of simplicity induced by this constraint is a corresponding reduction in cost. Up-front design efforts are reduced as are infrastructure requirements.
Deployability (+1)
Deployment of a monolithic binary can be as simple as copying a directory to a server or using a deploy feature in development tooling (although friends don’t let friends right-click deploy). The improvement of this capability is modest at best. We certainly can’t deploy with the same velocity of more granular architectures given the size of the deployment (the entire application, even for a small change) and the start-up time for an application degrades proportionately with the size of the code base.
Testability (+0.5)
Compared with the null style, testability can be slightly improved - but only slightly. There are few–if any–external dependencies to be aware of, in theory the entire codebase can be tested with minimal coordination cost.
Agility (-1)
A monolithic build artifact requires that any change require a redeployment of the entire system. Testing scope is higher and coordinating releases more difficult.
Scalability (-2)
This constraint introduces scalability challenges. The only available avenues towards scale revolve around either scaling up the hardware the application is running on or scaling out. The latter is severely constrained by the fact that the entire application must be replicated, not merely the handful of components responsible for the lion’s share of the load.
Abstraction (-2)
One key trade-off of the single, monolithic, codebase is that generally abstraction becomes a secondary concern (if at all). Without care, the code becomes tightly coupled with a high degree of connascence. Other constraints will balance this somewhat, but in the context of just this constraint, abstraction is degraded.
Elasticity (-3)
In the same way this constraint degrades scalability, elasticity is even more affected. Quickly responding to bursts in load become challenging as the entire application must be replicated, and the coarse granularity of the application will degrade startup times.
Fault-tolerance (-3)
Since the entire system resides in a single binary, fault-tolerance is adversely affected. Generally the system as a whole is healthy, or it is not. In more fine-grained architectures it’s possible for components to fail without bringing down the entire system.
Constraint: Monolithic Deployment Granularity
Although this constraint is superficially similar to a monolithic build artifact, there is a key distinction. A monolithic build artifact requires monolithic deployment granularity, but the inverse is not necessarily true. One notable example is the microservice mega-disasters I alluded to in earlier posts. Many times I have seen “microservices” architectures where all services must be deployed at the same time (often in a specific order). At that point, however, those systems can no longer be called microservices given that is a core constraint, they become distributed monoliths. This constraint cannot co-exist with the independent delployability constraint.
Simplicity (+1)
It is easier to reason about the deployment process at this granularity.
Cost (+0.5)
These pipelines are also generally cheaper to produce and maintain.
Deployability (-1)
Deployability is generally degraded as every change–even a minor one–requires a full redeployment of the system which reduces velocity and introduces risk.
Agility (-2)
As detailed in the deployability metric, velocity is reduced and risk in increased which reduces organizational agility.
Constraint: Domain Partitioning
This constraint defines how component boundaries are determined thus affecting component modularity in monolithic or distributed systems. In contrast to the technical partitioning constraint (where component boundaries are determined by technical categories) domain partitioning defines component boundaries along domain boundaries or at the bounded context.
The concept of a domain has its roots in Erik Evans' work on Domain-Driven Design in an attempt to manage growing complexity in software development. Fundamentally, Domain Partitioning is about finding natural seams (based on the topology of the business and problem domain as a whole) in the system for decomposition into modules, rather than artificial ones. In this case, the modular structure of the software itself mirrors the conceptual model of the business, which brings both potential benefits and trade-offs.
Domain-partitioned architectures are generally loosely coupled while providing very high cohesion. This constraint requires the organizational constraints of defined domains and domain-aligned teams.
Agility (+2)
This constraint improves business agility as many changes to a software system can be scoped to a single domain or bounded context which results in most changes being scoped to a single module which reduces testing scope, regression surface area, and changes typically require less coordination overhead. Change cost, risk, and complexity is lowered resulting in potential increased change velocity.
Evolvability (+1.5)
Changes to existing modules are heavily scoped to the domain boundaries or bounded context, which results in code that is easier to modify. Introducing significant areas of new functionality are often as simple as introducing new modules. In a monolithic architecture, domain-partioned systems are usually fairly easy to decompose providing additional evolvability towards more distributed architectures in the future.
Deployability (+1)
Deployment risk of domain-partitioned architectures is generally much lower given the highly-modular nature of systems introducing this constraint.
Testability (+1)
As explained above, testing scope and regression surface area are constrained, resulting in improved testability.
Fault-tolerance (+0.5)
Domain partitioning often reduces the blast radius of failures to a single domain or bounded context. This capability is modified by other architecture constraints.
Simplicity (+0.5)
By modeling the architecture of the system to mirror the business domain, simplicity is slightly improved. In terms of system components, the language of the business begins to match the language of the developers. Communication is improved, ownership of any area
Simplicity is only marginally improved, however, as building a domain-partitioned system requires first defining and documenting the various domains and their relationships. This is generally a long and difficult process (but, often, the reward is worth the effort). To add to this complexity, the organizational structure must be modified to mirror the domain structure. Conway's Law has repeatedly shown that the deployed system will mirror the organizational structure.is clearer, and overall maintainability of the system is improved.
Cost (-1)
To apply the domain-partitioning constraint, DDD ceremonies must be performed. These ceremonies are always time-consuming costly, thus this constraint introduces cost trade-offs.
Constraint: Separation of Concerns
This constraint further narrows the technical partitioning constraint by being more prescriptive around how layer boundaries and modularity are defined. This constraint defines that code is not simply defined by technical area, but also logical concern.
Cost (+2)
Development and maintenance costs are reduced by adding this level of modularity to code. Developers may develop deep domain expertise in business logic (or subset of the business logic) which further reduces cost.
Testability (+1)
This constraint further reduces testing scope for any given change.
Agility (+1)
Agility is improved as the code generally has better boundaries, reduced testing scope, and potentially change scope.
Simplicity (+1)
This constraint generally improves simplicity of development and maintenance of the code. It is well-defined way to develop software, and this constraint improves understandability of the system components as well.
Evolvability (+0.5)
Evolvability is slightly improved as a consequence of the factors detailed above.
Constraint: Partitioned Shared Database
This constraint states that the entire application utilizes a common database, however database tables or collections are segregated by system module boundaries. This segregation is typically implemented by placing database objects in discrete schemas or catalogs with individual access controls. A partitioned, shared database introduces some of the benefits of distributed databases without the additional cost and complexity.
Agility (+2)
The team responsible for any given module of the system also have full control, ownership, and autonomy over the module's respective database partition. The coordination cost associated with database changes is effectively eliminated and regression surface area is materially reduced. Consequently change scope, cost, and risk are reduced which increases velocity and the business's ability to respond quickly to change.
Cost (+1.5)
Generally sharing a single, shared database reduces licensing costs, hosting costs, and reduces development costs. Generally this also reduces data storage redundancy as there is much less need to replicate data to be visible to other application components. Cost-of-change is generally improved due to the reduced coordination cost this constraint provides.
Security (+1)
The ability to easily reduce raw database access to a single partition reduces risk associated with a breach and shrink's the system's attack surface area.
Deployability (+1)
Because coordination cost, change scope, and risk are reduced; deployment risk shrinks.
Evolvability (+0.5)
The reduced coordination cost and testing scope of a system with a database with clear boundaries slightly improves evolvability.
Fault-tolerance (-0.5)
A single database becomes a single point-of-failure. Although most database management systems bring high-availability configuration options, if one database (the only database) is unavailable, the entire system is unavailable.
Scalability (-0.5)
Databases are notoriously difficult to scale. Multiple databases responsible for different parts of the data provide some level of parallelism and increase total capacity, a single database may be limited to scaling up.
Simplicity (-0.5)
Although administration is simplified by virtue of having a single database to manage, defining and managing partitions requires additional effort at design time and runtime.
Elasticity (-2)
As a single, shared resource, the system as a whole becomes less elastic because there is a ceiling to the single database’s capacity.
Summary
The modular monolith can be a useful balance of the modularity of microservices against the simplicity of a monolith. This pattern is often useful starting place for a greenfield project where architectural capabilities remain uncertain or speed to market at this stage is more important that scalability. Typically proving your MVP and building a market are more immediate business concerns over massive scalability and elasticity. A modular monolith is also already part-way towards microservices. As your project grows and matures, it becomes almost trivial to carve off a single module into a standalone microservice for independent deployability and scalability. In fact, the modular monolith is a popular and pragmatic step in the process of decomposing an existing monolith into microservices.