CD & DevOps for Relational Databases Part II - How


In part I we explored the history and goals of DevOps and the Agile movement and the motivations for maturing your DBOps practice. In other words, part I addresses “mindset.” Let’s now look at this in practice and get into the “how” of DbOps, addressing the remaining “skillset” and “toolset” topics. Most crucially this involves not only understanding the tools you’ll be working with but also understanding the database. Poorly planned database changes have the potential to cause extended unwanted downtime and, if they break compatibility with the previous version of your app, can complicate rollbacks. Knowledge of RDBMS internals is crucial to moving “offline-breaking” database changes (database changes that require downtime and break compatability with previous versions of code) to “online-compatible” changes (database changes that do not introduce downtime and can be remain backward/forward compatible with code changes).
Change Management Approaches
The modern CI/CD toolset for databases largely fall into two categories of approach.
- Desired State Configuration (DSC)
- Database Migrations
Each has their trade-offs that must be evaluated but in summary it really boils down to how much control and visibility you want to delegate. As a (former) DBA, I remain deeply skeptical of DSC - let’s look at why.
Desired State Configuration
Here’s a real-world problem I recently faced. I built and maintain a SaaS CRM that many business rely on daily to run their business. Behind the scenes is a MySQL database that not only powers my application, but holds their data–the lifeblood of their business–in its metaphorical hands.
This started when I received a support ticket notifying me that email messages are being truncated in the history. The culprit was a single emoji character in the body of that message that was causing MySQL to choke. Everything following the emoji was discarded, resulting in some amount of data loss.
The root problem is a disagreement about what UTF-8 means. I understood UTF-8 to mean the entire range of the Unicode charset, but to MySQL it means a subset of the UTF8 charset; specifically MySQL’s implementation of UTF-8 can only address up to three-byte Unicode characters while the emoji are typically 4-byte. I’m not alone in my rage…

The fix is easy enough, I just need to change the character set for that table to be the ‘real’ UTF encoding. The Data-Definition Language (DDL) looks like this:
ALTER TABLE emails_text CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
So I run that script in my dev database, test my code, and prepare to commit and deploy my fixes. If I have a DSC tool, it will generate the change script by comparing the state of my dev database against a snapshot of prod. It will generate a delta script containing each atomic change and write those somewhere in my source tree.
Simple, right? Find the answer on SO, make the change in Dev, and my DB tooling will script the change and execute it as part of my deployment process.
Except, now my customers hate me and they left my platform. If I was an employee I might be reprimanded or fired but since it’s my company I’ll out of business.
The simplicity of this change was a lie. Migrations introduce a little bit more visibility and control into the process.
Migrations
Migrations will sequentially apply individual change scripts that, generally, you write and fall into two subcategories: Code migrations and SQL migrations. As a seasoned SQL developer and former DBA, I have generally been deeply skeptical of ORMs, the SQL they generate is generally garbage compared to what I could write but they’ve gotten significantly better over the years. As a developer, I can’t overlook the convenience and efficiency they bring in certain cases. For better or worse, I now use EntityFramework as my ORM in my CRM. EntityFramework offers a migration capability to scaffold, apply, and rollback changes in my dev environment and pipelines. The underlying process is similar to tools like FlyWay, RoundHouse, and a variety of others.
If I were to use EntityFramework Migrations?
Well, first I need to create a new migration. I would open the developer console and type something like:
dotnet ef migrations add AlterEmailsTextCharset
This will generate a new migration file named something like 20240223123456_AlterEmailsTextCharset.cs in the “Migrations” folder in my project. It will contain an Up() method where I can specify the specific changes I want to apply using the EF domain-specific language (DSL) or as SQL (which makes the most sense in this case.) It will also contain a Down() method to reverse the change if needed. It is in the Up() method where I will add my DDL.
protected override void Up(MigrationBuilder migrationBuilder)
{
migrationBuilder.Sql("ALTER TABLE emails_text CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;");
}
protected override void Down(MigrationBuilder migrationBuilder)
{
// If needed, provide a reverse operation here
}
In my pipeline script, I can execute the necessary migrations by calling
dotnet ef database update
This will execute the code in the Up() methods. EntityFramework Migrations manages state in a table called __EFMigrationsHistory and use this history to only apply new changes.
Another popular tool, Flyway, takes a slightly different approach to migrations. The process looks like this:
In your Flyway project directory, create a new SQL migration file. The file should follow the naming convention “V{version}__{description}.sql” where “{version}” is a unique version number and “{description}” is a description of the migration. For example: V1__AlterEmailsTextCharset.sql
Then I will edit this file by opening the newly created SQL migration file and writing my SQL script:
ALTER TABLE emails_text CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Then I would use the Flyway command-line tool or build tool plugin to run the migrations. The flyway configuration would need to be specified, including the connection details and migration location. On the command line tool, it might look like this:
flyway -url=jdbc:mysql://prod-db:3306/your_database -user=${secret} -password=${secret} -locations=filesystem:/path/to/migrations migrate
By adopting migrations, I’ve taken more deliberate control over the change scripts and the order they run in. That said. I’m still out of business (or fired). Why?
DDL - The Rest of the Story
The main table affected by this issue happens to be the single largest table in my database by multiple standard deviations, the emails_text table. The table itself contains about 3,500,000 records occupying about 170 GB of disk space. By today’s standards, it is a small-to-medium sized table but it is still big enough to sink my business.
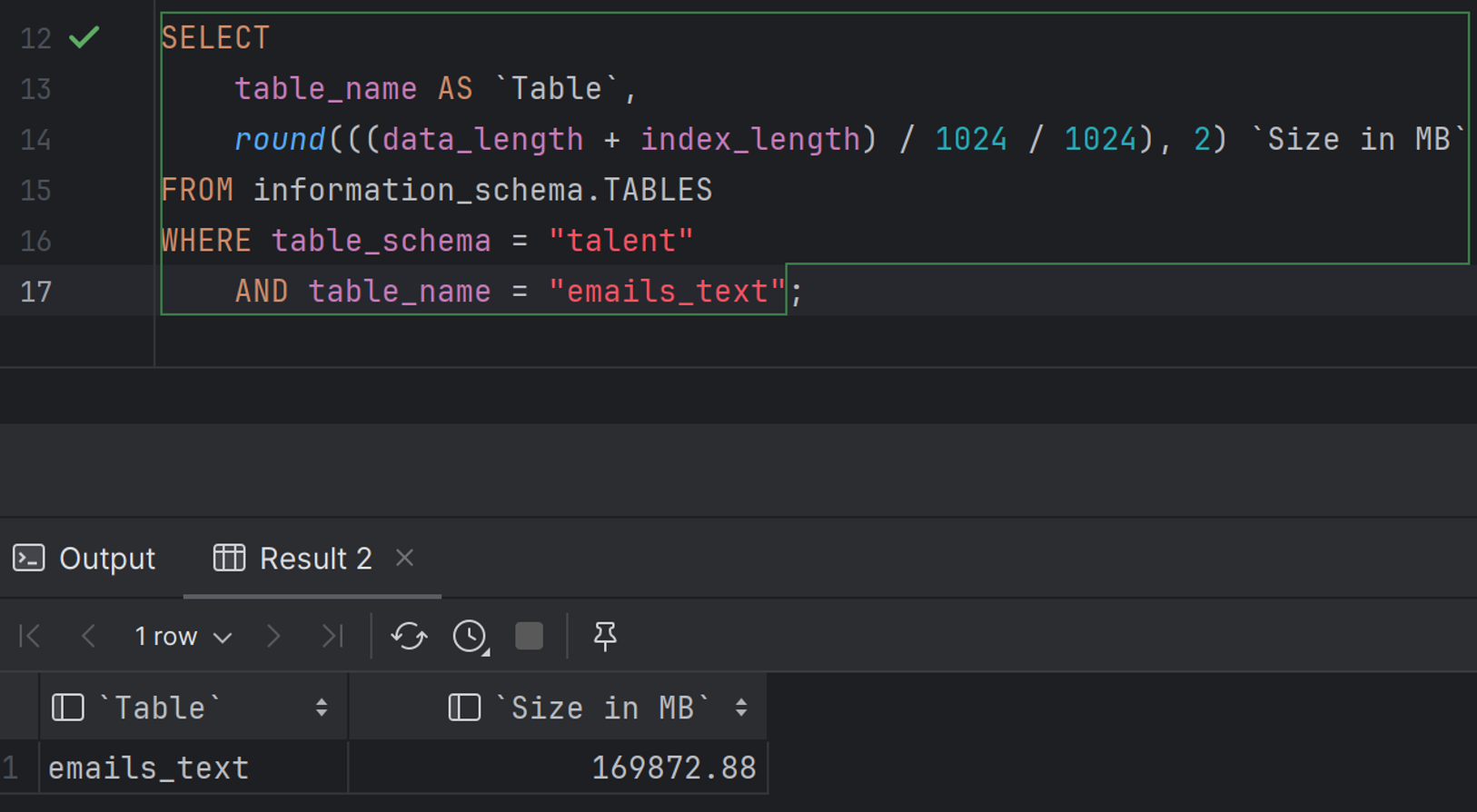
To apply such a change, the DBMS must first allocate an exclusive lock on the table. This will prevent any other process from reading or writing to the table until the DDL has finished executing. For the purpose of this post, I cloned my production DB and ran this script directly and killed it after 18 hours. I have no idea how long this will actually take to run in my production environment.
If I put this change in my pipeline and deployed to production then, at first, users will notice that certain pages that include email history will stop loading since their reads will be blocked by the exclusive table lock. In the background, a crucial component of the application–sending and receiving emails–will grind to a halt. Read/Write requests will queue up until the connections are saturated and, at this point, my entire application will go offline and remain offline until the DDL finishes executing. My application is architected as a Modular Monolith, meaning there are clear domain-driven module boundaries, but the underlying database server is shared. You may be in a more distributed environment, so that blast radius might be restricted, but the implications remain the same.
Admittedly the gravity of this kind of change may be obvious at design-time, but changes as simple as adding or changing a column can have similar downtime consequences.
Managing Database Changes

We cannot escape the reality that many database changes can break production for long periods of time. The first and most important step is to shift this feedback left. Blue/green and Canary deployment strategies work well for stateless code changes but neither will give you the necessary feedback in time to avoid catastrophe when offline database changes are involved. We need a new, final quality gate to break the build before going to production. Based on your application’s SLA, determine the maximum acceptable downtime (My CRM’s SLA is 99.9% uptime, which means less than 90 seconds of downtime per day is tolerable.)
This quality gate will deploy to a pre-staging environment that contains a clone of the production database. When the DB Migration stage runs, my pipeline monitors the database for extended blocking and will kill the process after 90 seconds which breaks the build. In practice, this will look different on different DBMS platforms but the key thing is the script can run for longer than 90 seconds, it just can’t block for more than 90 seconds.
A broken build on the DB migration stage is my early warning that additional care and skill must go into planning and designing the changes. When you find yourself in this situation, you have two available options:
Option 1 is to pair with–or assign the task to–a DBA. An experienced DBA will not only know the risks of any given change, but they will know the strategies to mitigate this risk. The trade-off for this approach is your overall agility is reduced as the DBA becomes a new bottleneck in the process. There’s a reason many developers jokingly say that what DBA really stands for is “Don’t Bother Asking.”
Option 2 is to level up your DB skills. To be truly agile and effective in our practice of DevOps, we need more than proficiency with the tool (Dev) we need proficiency with the database (Ops). Since you’re still reading, this will be my focus.
Database Change Categories
Database changes fall into a two-dimensional matrix. On one axis in compatibility, on the other is availability.
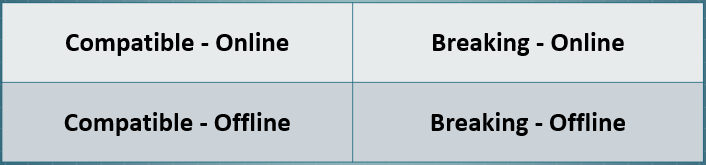
Compatible Changes
A compatible change is defined as one that can be applied to the database without breaking compatibility between the database and the current or future version of the application. Compatible changes are often–but not exclusively–stateless.
A stateless change is one that doesn’t modify database state. Adding an index, for example, or changing the definition of a stored procedure or UDF are generally stateless changes. They may also be compatible so long as the interface of the UDF or procedure doesn’t change.
A stateful change will modify the data in some way. Adding a column to an existing table (or adding/populating a new table) will technically be stateful, but compatibility will depend. Simply adding a column will not generally affect the existing version of the app (so long as you aren’t using SELECT * FROM... anywhere… and you’re not, right?)

Compatible changes bring two large advantages. First they can be deployed independent of the application code. We’ll talk about why this is useful shortly.
Second, they generally don’t need to be rolled back should the application deployment fail.
Breaking Changes
A breaking change is any change that necessarily requires a code change to be applied in lock-step and one that must be rolled back if the application deployment fails. Breaking changes are typically–but not exclusively–relating to database refactoring.

Perhaps your had a field called Name but later decided it would be better to break that into FirstName and LastName and your script adds the new columns, migrates the data into the new columns, then drops the Name column. Or, perhaps you had a table that contained the columns PrimaryEmail AlternateEmail1 and AlternateEmail2 and you decided that you want to normalize that table and support more than three email addresses by creating a child table, migrating the data, then dropping the old columns.

In either case, the breaking change must be applied, then the code deployed. If the deployment fails both the code and the database changes must be rolled back to return the system to it’s last known good state.
Online & Offline Changes
A change is considered “online” if the change can be applied without impacting availability. An Offline change is one that that will take long enough to violate the your SLA.
Just Enough SQL Internals
Understanding when and why a change will become an offline change requires understanding a few under-the-hood details of how a DBMS works.
Physical Storage/Organization
The fundamental unit of storage for both tables and indexes in SQL databases is the page. Pages occupy a fixed amount of space on disk and in memory whether they are full, empty, or somewhere in between. I/O operations also typically take place on the page level. In the absence of a clustered or primary index, the pages are organized in a heap. Once an index is created, the index (or the table, if the index is a primary/clustered) is structured as a B-Tree with the leaf nodes being the pages themselves representing the data stored and the intermediate nodes supporting fast access to the index keys. At the leaf-level, pages are also double-linked lists to facilitate range-scanning operations.
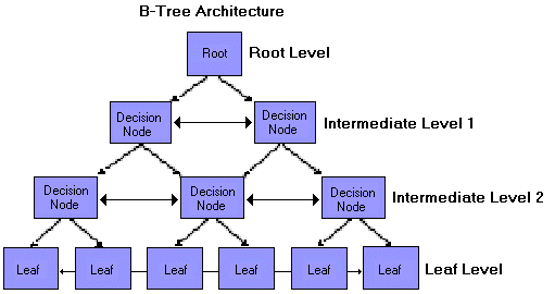
The key distinctions between a primary/clustered index and a secondary/non-clustered index are:
- A primary/clustered index is keyed on a subset of columns but also contains all non-key columns in the row. Effectively this index is the table.
- A secondary/non-clustered index contains just the index key and a pointer to the primary/clustered index (or a rowId in a heap)
- Because the primary/clustered index is the table itself, there can be only one.

The analogy I like to use for primary/clustered indexes is that of a phone book. It is keyed on last name, first name but contains all data within each page.

Index Overhead
Although indexes can introduce efficiency into record seek operations, they introduce overhead. The most obvious overhead is the need to keep secondary indexes in sync with the table itself. An INSERT or DELETE operation on the table naturally requires similar operations to take place on all related indexes but those secondary operations can become quite expensive, relatively speaking, and introduce long-term performance consequences.
Remember that a page is a fixed size. Should a row need to be inserted in the middle of an already full page the database must perform a Page Split.
- A new page must be allocated (this may involve growing files)
- 50% of the contents of the full page must be moved to the new page
- The new data is written to a page
- This is repeated for every other affected index
An I/O operation that would normally be a few dozen bytes begins to require several kilobytes of I/O very quickly. Put more directly, page splits introduce a 100x-1000x increase in IO for write operations while reducing concurrency and throughput. The consequences scale quickly. This is the short-term impact.
Long term, page splits degrade performance and resource utilization. Remember that pages occupy a fixed size in memory and on disk; and that I/O is almost always a page-level operation. If you have 10,000,000 half-full, 8k pages on disk that need to be read into memory, then your server did 40GB of extra, random physical I/O to read nothing. That is also (potentially) 40GB of empty space in the buffer pool (server memory). Generally indexes should be carefully designed, monitored, and regularly rebuilt or defragmented to reduce this long-term overhead.
Lock Compatibility
Every operation on a database table requires a lock of some kind. The overhead of a single page-split causes individual transactions to take longer with the database holding locks (typically update or exclusive locks) longer than we would ideally like for optimal concurrency, the typical scope of these locks (page or row-level) limits contention. Contention can further be reduced if a connection opts to perform “dirty reads” if throughput is more important than consistency. Dirty reads, however, still require a lock on a row, table, or page; just one that is “compatible” with other locks on the resource. At a minimum, the “dirty” read query still must allocate a “Schema Stability” lock. In other words, “you can change data while I read, you can delete data while I read, but you can’t change the table while I read.” Schema changes require a “Schema Modify” lock which is incompatible with any other kind of lock. While a SCH-M lock is held on a table, all other queries will be blocked until the lock is released or their connection times out.
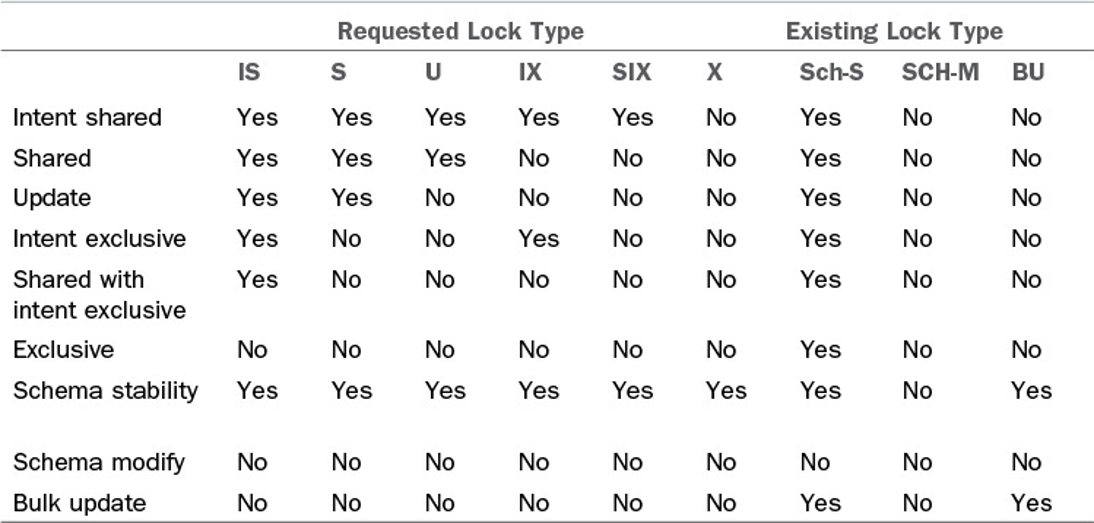
While the overhead of a single page-split is rarely palpable, schema changes often involve reorganizing every page in a table which can be incredibly expensive on large tables. Altering a table to change the character set will require rewriting every single page of the table and the indexes, several hundred GB of I/O over a period of hours while holding an exclusive SCH-M lock. What’s worse, attempting to cancel this operation will require a lengthy rollback operation.
Strategies for Reclassifying Changes
The successful adoption of DBOps as part of your DevOps strategy relies on moving as many changes as possible into the Online-Compatible quadrant.
Offline Compatible migrations are low risk but deployments are typically constrained to maintenance windows which reduces agility. Offline breaking changes are the most risky. Not only is availability already a concern, but rollbacks may also be time consuming. These must be avoided unless absolutely necessary. The good news is that, generally, breaking and offline changes can be written as online compatible changes.
Offline Compatible to Online Compatible
The example of my emails_text table is a change that is compatible (my ORM and application doesn’t care if the table stores UTF8 or UTF16mb4 - it’s just text to my application). Any kind of ALTER TABLE statement will first require Schema Modify lock (or equivariant) to be acquired on the table. All other lock types are incompatible meaning any other attempts to access that table will be blocked. Under the hood the storage engine of the DBMS must do a great deal of work to reorganize the data across the pages.
Making this an online change requires we avoid the long-duration Schema Modify lock. There’s no way to specify an ALTER TABLE with nolock but we can redirect our locks elsewhere to avoid contention. Consider this approach:
- Make a new table with the appropriate schema
CREATE TABLE `emails_text_migration` (
`email_id` INT UNSIGNED NOT NULL,
`from_addr` varchar(255) DEFAULT NULL,
`reply_to_addr` varchar(255) DEFAULT NULL,
`to_addrs` text,
`cc_addrs` text,
`bcc_addrs` text,
`description` longtext,
`description_html` longtext,
`raw_source` longtext,
`deleted` tinyint(1) DEFAULT '0',
PRIMARY KEY (`email_id`),
KEY `emails_textfromaddr` (`from_addr`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Next we need to populate this new table. Copying hundreds of gigs of data all at once will throttle I/O on the server (while holding at least a shared lock) so we need to think about two things:
- How to manage concurrency while copying the data
- How to keep these two tables in sync.
--This is probably a bad idea
INSERT INTO emails_text_migration
SELECT * FROM emails_text
For managing concurrency, I find it best to batch the reads/writes. For keeping both tables in sync, we must come up with a strategy. If you want to trigger a DBA, use the word “trigger.” Triggers have a bad reputation both because often they are a hack and because they cause code execution beyond your explicit instructions. That said, they can be useful and this is one of those cases.
My emails_text folder is pretty much a write-only table so a trigger similar to the following would work:
DELIMITER //
CREATE TRIGGER `emails_text_copy_trigger` AFTER INSERT ON `emails_text`
FOR EACH ROW
BEGIN
INSERT IGNORE INTO `emails_text_migration` VALUES (NEW.email_id, NEW.from_addr, NEW.reply_to_addr, NEW.to_addrs, NEW.cc_addrs, NEW.bcc_addrs, NEW.description, NEW.description_html, NEW.raw_source, NEW.deleted);
END; //
DELIMITER ;
Now any new writes will automatically copy over to my new table. Next I want to copy rows from the old table to the new table in batches. Determining optimal batch size requires some experimentation but 1,000-10,000 seems to be a good range to experiment with. My table primary/clustered index key is a monotonically increasing integer which makes this fairly easy, but use whatever key ranges make sense for your purposes - just remember to try to stick to sequential I/O on the primary/clustered index.
-- Get the maximum email_id value from emails_text
SET @max_email_id = (SELECT MAX(email_id) FROM emails_text);
-- Loop to copy rows in batches
SET @start_email_id = 1;
SET @batch_size = 5000;
WHILE @start_email_id <= @max_email_id DO
INSERT IGNORE INTO `emails_text_migration`
SELECT * FROM `emails_text`
WHERE `email_id` BETWEEN @start_email_id AND (@start_email_id + @batch_size - 1);
SET @start_email_id = @start_email_id + @batch_size;
END WHILE;
Although the row range of this script is not guaranteed to include every single row, the trigger is catching records that are written during the migration.
Once the migration is complete, it’s a simple case of swapping out the tables. This is the only point in the process where an application-blocking lock is acquired, but the duration is very short. The migration step would look something like this:
START TRANSACTION;
-- Acquire exclusive locks
LOCK TABLES `emails_text` WRITE, `emails_text_migration` WRITE;
-- Rename tables and validate counts
RENAME TABLE `emails_text` TO `emails_text_old`, `emails_text_migration` TO `emails_text`;
-- Validate counts (optional)
-- You can compare row counts between emails_text and emails_text_old here
-- Drop the old trigger
DROP TRIGGER `emails_text_copy_trigger`;
-- Optinally create a new trigger to copy inserts/updates/deletes to emails_text_old
-- (You need to write this trigger similar to the previous one)
-- Commit the transaction
COMMIT;
-- Release locks
UNLOCK TABLES;
Likewise, a rollback is very straightforward. Just swap the two tables back.
START TRANSACTION;
-- Acquire exclusive locks
LOCK TABLES `emails_text` WRITE, `emails_text_old` WRITE;
-- Rename tables back to their original names
RENAME TABLE `emails_text` TO `emails_text_migration`, `emails_text_old` TO `emails_text`;
-- Drop the new trigger on `emails_text`
-- Recreate the old trigger on `emails_text`
-- Commit the transaction
COMMIT;
-- Release locks
UNLOCK TABLES;
There are some optional steps here, but the key is the ability to make a significant and time consuming change without impacting performance or availability.
Online Breaking to Online Compatible
What about a breaking change, similar to the database refactoring examples above?
perhaps you had a table that contained the columns
PrimaryEmailAlternateEmail1andAlternateEmail2and you decided that you want to normalize that table and support more than three email addresses by creating a child table, migrating the data, then dropping the old columns.
Again, we can break this process up:
- Create the child table
- Create the trigger
- Migrate the data in batches
At this point, the code that will work with the new tables can be released, but a simple rollback in feasible. At some point in the future, the old columns may be dropped but can be left in place to ensure compatibility in the event of a rollback.
Other Strategies for Phased Changes
Whether I’m building a monolith or a microservice, I like to use the repository pattern. A single class for each domain entity whose single purpose is talking to the database. My repository will handle I/O database I/O and map database entities to the application object model equivariant. This introduces a layer of abstraction between my relational model and my object model. In this way, I can make an online compatible change to the database and deploy this separately and confidently to production without changing application code or behavior. With my new data model in place, I can make a subsequent change and deployment that contains the large changes to the rest of my application.
By breaking these changes down into smaller, bite-sized steps I can reduce my deployment risk and ensure rollback paths every step of the way.
What about NoSQL?

About a decade or so ago, there was a spike in interest in “schemaless” databases. These are useful tools, but not a panacea.
The reality is, whether your application has columns or documents, you have a schema and schema changes must be managed.
Imagine this CRM was built on top of a schemaless database. Perhaps, at one point, address was simply a string, then it became an object.
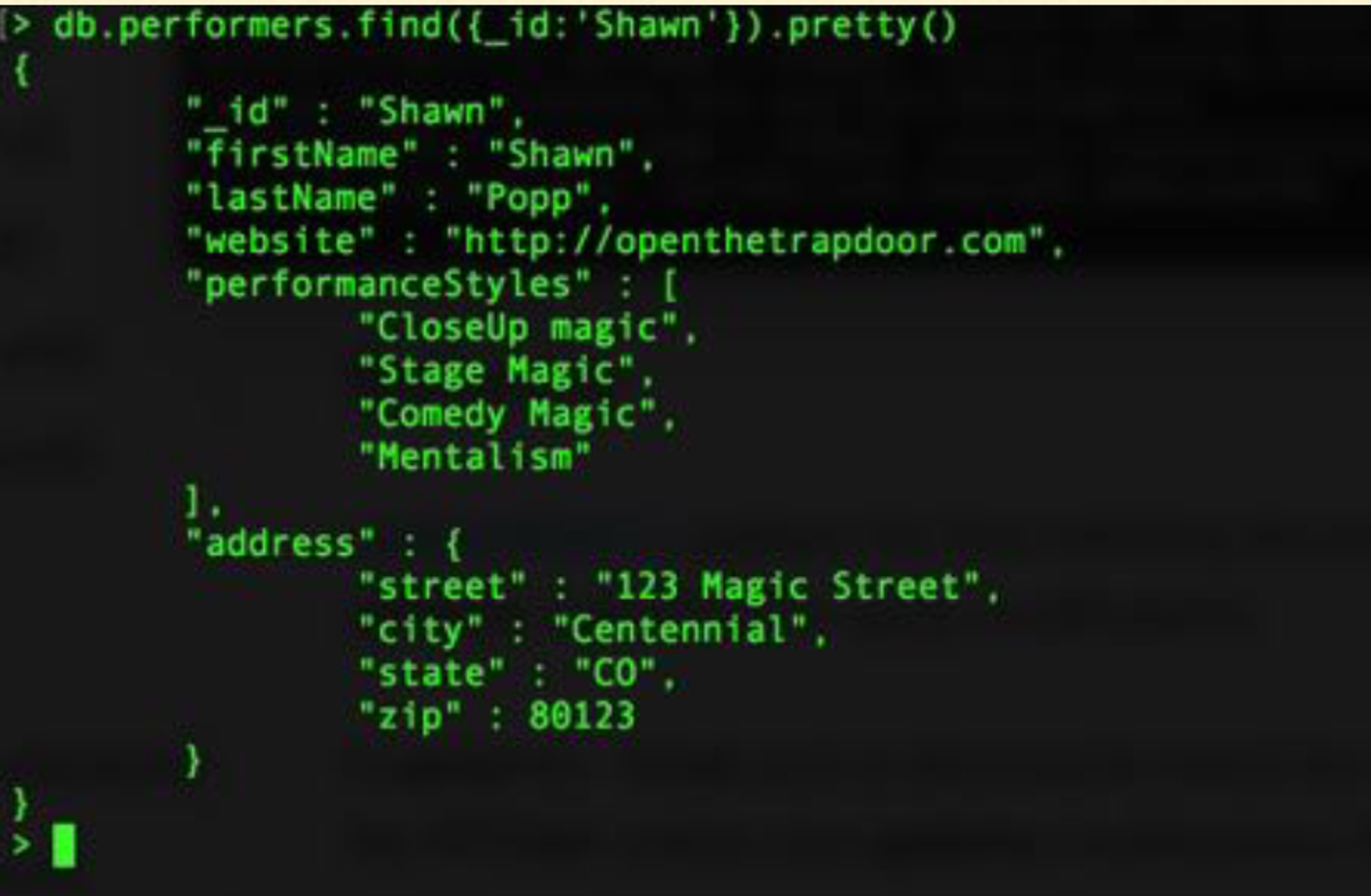
Then it became an array of objects
No alter tables, right?
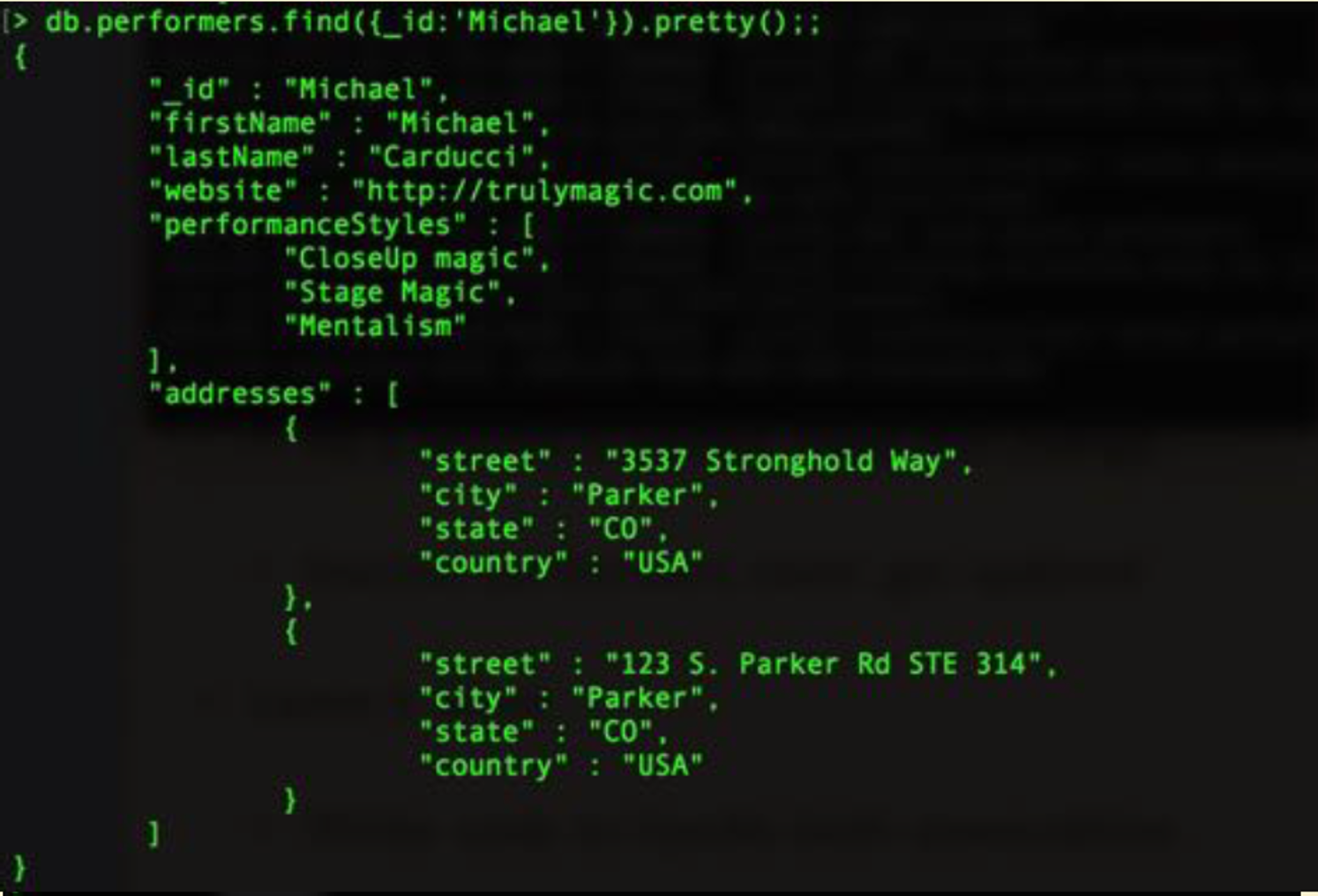
Except there’s still as schema - it’s just inconsistent now. We still have to migrate. The problems exist but the options are different

Options:
- Leave the schema inconsistent (Thus, writing code that knows how to handle both address and addresses)
- Migrate all documents when the schema changes
- Migrate on Demand
- As a record is loaded, make the change
- Inactive records are never updated
In other words, relational schema or not, we want to think about design and we will have to manage migrations at some point and in one form or another.
Conclusion
DevOps is a valuable practice and, if adopted mindfully, can massively increase overall agility. Agility within databases introduces challenges, but the problems are absolutely tractable. They key is while the tools are valuable their utility is constrained by the skill of the hands that wield them. If you’ve read this far, you already know more about Databases than 90% of developers and you’re better positioned to get faster feedback and remove more bottlenecks in your software delivery process. It’s not always easy but the benefits are vast.
General Best Practices
- Practice Continuous Integration
- Practice Continuous Delivery
- DB Deployment Quality Gate
- Break up Big Changes
- Avoid Leaky Abstractions
- Use Architecture Unit Tests
PostScript: Emoji Support
It took a few weeks of effort and planning, but the change was deployed safely during peak season with zero downtime. The performers are happy.

Remember, the most important and valuable feedback is customer feedback. Investment into pipelines, automation, and quality gates enables me to get working software in the hands of my customers faster and thus feedback on the value of my software faster.
“Our highest priority is early and continuous delivery of valuable software” -The Agile Manifesto
CI/CD, DevOps, and DBOps requires some up-front investment, but sometimes you need to go slower now to go faster later. 10 years into the life of this product and still deploying several times per week with 100% confidence is a good feeling. This agility didn’t come from a framework, or a checklist, or a blog post; it came from a commitment to process improvement and regular action-oriented retrospectives. I’ll say it again: “Don’t do agile; be agile.”