Building a Modular Monolith Part I


Ask most developers these days “Which is better: Monolith or Microservices?” you will likely receive a prompt and definitive “Microservices. Hands down.” The term monolith has become a pejorative; a four-letter word in software architecture circles. The folk-wisdom criticisms are not entirely undeserved, after all there are a lot of bad monoliths out there; unmaintainable, untestable, brittle to the point of personifying a Jenga tower of code. Many (perhaps most) non-trivial monoliths in the wild today could be classified as a Big Ball of Mud. I submit that most criticisms of monolithic software architecture would be more accurately targeted at Ball of Mud architectures. A monolithic deployment granularity doesn’t necessarily presage a Ball of Mud and furthermore, adopting a distributed architecture (such as microservices) does not automatically inoculate a system against evolving into a Ball of Mud.
The term, which has become a formal anti-pattern, was popularized in a 1997 paper, written by Brian Foote and Joseph Yoder:
A Big Ball of Mud is a haphazardly structured, sprawling, sloppy, duct-tape-and-bailing-wire, spaghetti-code jungle. These systems show unmistakable signs of unregulated growth, and repeated, expedient repair. Information is shared promiscuously among distant elements of the system, often to the point where nearly all the important information becomes global or duplicated.
The overall structure of the system may never have been well defined.
If it was, it may have eroded beyond recognition. Programmars with a shred of architectural sensibility shun these quagmires. Only those who are unconcerned about architecture, and, perhaps, are comfortable with the inertia of the day-to-day chore of patching the holes in these failing dikes, are content to work on such systems.
-Brian Foote and Joseph Yoder
Microservices vs (Layered) Monoliths
In Mark Richards’ and Neal Ford’s excellent book, Fundamentals of Software Architecture they introduce a rating-scheme which I had the privilege of watching evolve over my years as a speaker on the NoFluffJustStuff Conference Tour. In their book, the authors assign a 1-5 star rating scoring how a given architectural pattern performs against different architectural characteristics. The contrast between the de-facto monolithic architecture (layered) architecture with the microservices architecture couldn’t be more stark:
| Architecture Characteristic | Layered Monolith | Microservices |
|---|---|---|
| Partitioning Type | Technical | Domain |
| Number of Quanta | 1 | 1 to Many |
| Deployability | ⭐ | ⭐ ⭐ ⭐ ⭐ |
| Elasticity | ⭐ | ⭐ ⭐ ⭐ ⭐ ⭐ |
| Evolutionary | ⭐ | ⭐ ⭐ ⭐ ⭐ ⭐ |
| Fault Tolerance | ⭐ | ⭐ ⭐ ⭐ ⭐ |
| Modularity | ⭐ | ⭐ ⭐ ⭐ ⭐ ⭐ |
| Overall Cost | ⭐ ⭐ ⭐ ⭐ ⭐ | ⭐ |
| Performance | ⭐ ⭐ | ⭐ ⭐ |
| Reliability | ⭐ ⭐ ⭐ | ⭐ ⭐ ⭐ ⭐ |
| Scalability | ⭐ | ⭐ ⭐ ⭐ ⭐ ⭐ |
| Simplicity | ⭐ ⭐ ⭐ ⭐ ⭐ | ⭐ |
| Testability | ⭐ ⭐ | ⭐ ⭐ ⭐ ⭐ |
Many (although certainly not all) of the low ratings are a consequence of how the code within the monolith is architected. The decision to adopt technical partitioning (as opposed to domain partitioning) results in code entirely organized by layer (e.g. Presentation Layer, Business Layer, Persistence Layer, Database, etc.). Code in each layer might be well-organized, but generally there are few restrictions preventing a developer from taking shortcuts that result in coupling of code across modules or database tables. The result is code that is poorly modularized, difficult to change/evolve, difficult to test (degrading reliability), and consequently difficult to release.
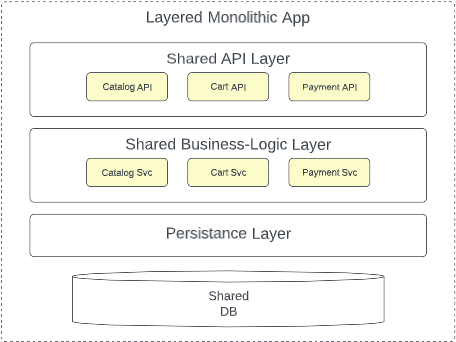
A microservice architecture introduces the concept of domain partitioning where each service is a single purpose, independently deployable (and scalable) unit of software that does one thing very well. Naturally, a microservice architecture improves elasticity and scalability as each service can be independently scaled unconstrained by it’s shared-nothing architecture. The “micro” nature of each service dramatically reduces startup time, improving elasticity. These are clear benefits of a fine-grained distributed architecture that cannot be easily realized by a monolithic deployment model.
A microservice has physical boundaries reducing the potential of code coupling to all but the service’s well-defined interface and each microservice typically owns its own data which prevents coupling at the database level. These boundaries make it easier to evolve a given microservice confidently and provide clear testing scope to each change. These boundaries make the microservices architecture more deployable, testable, evolvable, and fault-tolerant. It is, perhaps, these characteristics that can be most improved by applying the lessons learned from the microservices architecture to a new type of monolith, the modular monolith.
Introducing the Modular Monolith
The modular monolith is not a new concept. It reality, it is just a set of architectural constraints chosen to elicit particular architectural characteristics. It begins with an emphasis on the idea of modular programming:
Modular programming is a software design technique that emphasizes separating the functionality of a program into independent, interchangeable modules, such that each contains everything necessary to execute only one aspect of the desired functionality. A module interface expresses the elements that are provided and required by the module. The elements defined in the interface are detectable by other modules. The implementation contains the working code that corresponds to the elements declared in the interface.
The key takeaways are:
- Modules must be independent and interchangeable
- Modules must be self-contained
- Modules must have a defined interface
Like many words in our industry, the term “module” is overloaded. Arguably the presentation layer or business logic layer of the classic layered monolith could be considered modules. The modular monolith becomes opinionated on what constitutes a module, adopting a key idea from microservices; domain partitioning.
Each module in a modular monolith wholly represents a specific sub-domain of the application. These modules encapsulate all functionality necessary to satisfy that given subdomain, exposing only a uniform public interface. The “host” application can interact with that interface but everything else–ideally including the module’s data–is completely hidden from the rest of the application. Essentially the modular monolith creates vertical slices of the monolithic application with boundaries as rigid as those found in microservices.
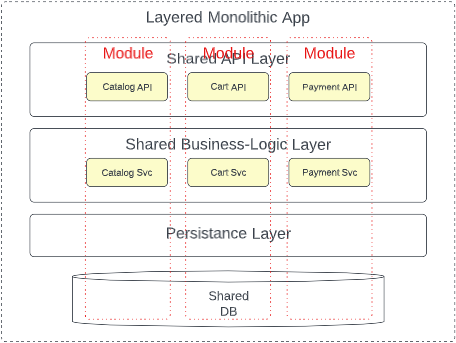
In essence, the each module in a modular monolith roughly corresponds to a microservice. It is a separate package or assembly encapsulating everything necessary to deliver that particular slice of functionality but the modular monolith introduces a tradeoff. By adopting the same modularity and encapsulation of the microservices architecture, evolvability, testability, modularity, reliability, and even deployability is improved. Because the monolithic deployment unit is maintained the strong cost and simplicity of the monolith is retained. Of course, keeping these modules within the single deployment unit, elasticity, scalability, and fault-tolerance remain the same or only improve marginally.
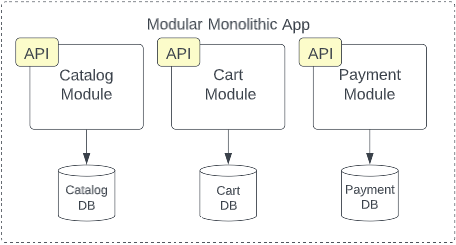
The modular monolith is a often great place to start a greenfield project. Typically proving your MVP and building a market are more immediate business concerns over massive scalability and elasticity. A modular monolith is also already part-way towards microservices. As your project grows and matures, it becomes almost trivial to carve off a single module into a standalone microservice for independent deployability and scalability. In fact, the modular monolith is a popular and pragmatic step in the process of decomposing an existing monolith into microservices.
Conclusion
“The reports of my death are greatly exaggerated.”
-Mark Twain
Contrary to the prevailing folk-wisdom, the monolith is not dead. The modular monolith provides a useful compromise between monoliths and microservices that might prove very useful in your new project, or in your attempts to tame an existing big ball of mud nightmare.
2020 prediction: Monolithic applications will be back in style after people discover the drawbacks of distributed monolithic applications.
— Kelsey Hightower (@kelseyhightower) December 11, 2017
In Part II of this series we begin building the foundation of a modular monolith in c# and share the github repo.