A Practical Path to AI Agentic Systems (Part II)


In Part I we explored the idea of AI agentic systems, current paths being explored, and the roadblocks present in those paths. If the API-driven approach is “too hard” and the browser-driven approach is “too soft” does there exist an approach that is “just right?”
Rather than looking at APIs vs browser-driven approaches as an either-or proposition, we should be exploring the intersection of the two approaches.
It turns out that the intersection of those two sets has existed for decades, we’ve just chosen to ignore it because it hasn’t historically been relevant.
A Reintroduction to REST
REST just might be the most widely misunderstood and maligned idea in our industry. This is not a claim I make lightly as I am well-aware there is a great deal of competition for that top spot. Agile is certainly a contender, as is DevOps, TDD, along with countless others.
There are a lot of opinions online, which can make understanding REST a challenge for even the most dedicated practitioner. Rather than rehash or debate the various opinions, let’s look at the facts.
REST, as originally defined, has nothing to do with APIs, it is an architectural style that has been applied to the world-wide web itself. What is an architectural style? In simple terms, you can think of an architectural style as a more precisely defined architectural pattern. Architectural styles are defined by governing rules or constraints. Constraints are the mechanism through which an architectural style induces desirable architectural capabilities (or, simply, -illities). The REST architectural style is defined by the following constraints:
- The Client/Server Constraint
- The Stateless Constraint
- The Cache Constraint
- The Layered System Constraint
- The Uniform Interface Constraint
- The Optional Code-on-Demand Constraint
Most “RESTful API” systems follow a client/server topology, are often stateless, sometimes implement caching, and frequently take advantage of the layered system constraint (gateways, proxies, facades, legacy-system wrappers, etc.). The code-on-demand constraint is not particularly relevant here just yet, but it’s optional so we can simply ignore it for the time being. That leaves the uniform interface constraint as the universal violation in every REST-in-name-only API implementation.
Because so many REST-in-name-only APIs exist (virtually all of them), Leonard Richardson created a maturity model to evaluate how closely a given API conforms to the uniform interface constraint with level 0 being a free-for-all (do whatever you want with your API, just know that every single client will require significant effort to interact with your API) to level 3 (an API that fully conforms to the REST architectural style).
Let’s explore the uniform interface in more detail.
Uniform Interface - More than PUT vs POST
Typically, when we think of the interface of an “REST” API, we think in terms of the the HTTP Interface (GET, POST, PUT, PATCH, DELETE, Etc.) but REST doesn’t actually prescribe HTTP, that’s an implementation detail.
So, what is the REST uniform interface?
The Uniform Interface Constraint is defined by interface constraints.
The Resource Abstraction
An API that adopts the REST architectural style does not directly expose methods or function calls. Instead, REST deals purely with resources. A resource is anything in a software system’s domain that is important enough to give a name.
I built and maintain a SaaS CRM for professional entertainers, within that domain there exist several classes of entity:
- A Contact
- An Event
- An Organization
- A Call
- A Task
- etc.
These are all information resources that, in the application, map to one-or-more tables in a relational database (n.b. it is not always a 1:1 mapping). Non-Information_resources also exist but are not germane to this section.
We identify resources with URIS. Within my database, a contact may have a numeric key (e.g. 12345) or an alphanumeric key (e.g. 470f3e5f-82f8-4559-8841-a39bc40866e2) but this identifier only has value within the database and foreign-key-constraint metadata. To make these keys valuable outside of a given database implementation we wrap them in useful metadata, namely:
- a scheme (Typically the protocol the server speaks e.g.
https://) - an authority (Typically a domain on the web that you control e.g.
example.com) - a hierarchical system to organize resources; a conceptual information space where you can define resource identifiers within your organizational namespace (e.g.
/Contactrepresents the collection of things we call ‘contacts’ or/Contact/Id/12345represents a specific instance of the/Contactcollection).
Through this uniform approach to resource identifiers, if a client knows the identity of the resource, it can begin to interact with it. Given the identifier https://example.com/Contact/Id/12345 the client may opt to retrieve the resource with that identity from a local cache, or it may use the information embedded in the identifier to connect to the server (example.com) using the https protocol and GET /Contact/Id/12345. Much of what is needed for this interaction is in-band as part of the Uniform Resource Identifier (URI) standard.
We manipulate resources through representations. A GET operation on the previous URI is expected to return a serialization of the resource that represents the current state of the object. Such an interaction might look like this:
GET /Contact/Id/12345
Host: example.com
Accept: application/json
...
200 OK
Content-Type: application/json
...
{
"id": "https://example.com/Contact/Id/12345",
"givenName": "Michael",
"familyName": "Carducci",
"email": "Michael <at> Magician.Codes",
"lastContact": "2024-12-21",
"tags": [
{
"id": "https://example.com/Tag/Name/past-clients",
"name": "Past Clients"
},
...
],
...
}
Notice how I reference related tags by their URIs rather than database keys (I also include a minimum of the name to provide a necessary label for a UI that would otherwise require a separate fetch for each tag). I can still retrieve those linked resources, if necessary, but I have included enough of each tag in the resource representation to make such an action purely optional.
Imagine I wanted to update the LastContact date of the contact resource. I could gin up an endpoint along the lines of /Contact/Id/12345/UpdateLastContact?date=2025-02-28 but this would violate the uniform interface constraint. Instead, the REST way would be to send the server a new representation of state:
PUT /Contact/Id/12345
Host: example.com
Content-Type: application/json
...
{
"id": "https://example.com/Contact/Id/12345",
"givenName": "Michael",
"familyName": "Carducci",
"email": "Michael <at> Magician.Codes",
"lastContact": "2025-02-28",
"tags": [
{
"id": "https://example.com/Tag/Name/past-clients",
"name": "Past Clients"
},
...
],
...
}
Keep in mind that this approach is not optimized for network efficiency, it is optimized for generality (although it’s worth mentioning that the PATCH request method exists for a more network-efficient resource update). Not every API need to (or should) optimize for generality, but agent-ready APIs probably should. Interoperability is something that our potential AI agents desperately need at this time.
A very important detail is that URIs must be stable in other words, a URI should not change when your tech stack changes, or your cloud implementation, or the applications behavior, or the serialization, or your database, or anything else. This is not the common practice, typically we try to mitigate breaking changes in bespoke ways (often out of ignorance or apathy of alternatives). It’s common to see URIs in the form of https://example.com/api/v2/Contact/Id/12345 but this means when the representation of the resource changes, the identity changes. Imagine the chaos of a distributed system where one database regularly changes primary keys of records. It would be a huge challenge to put humpty-dumpty together again. Conversely, REST provides a path where such versioning is unneccessary.
The Resource Abstraction, with strong, stable identifiers, results in a Level 1 system, according to the Richardson Maturity Model.
Semantically Constrained Actions
The http(s)?:// scheme provides interaction methods that are well-defined by the protocol spec. GET is defined to be safe (no side-effects will be induced by the request) and thus idempotent (a GET that is repeated or retried multiple times will yield the same result as it would if the request were made once). POST is defined as unsafe (may have side-effects) and explicitly not idempotent (repeating a POST request may result in duplication of behavior such as creating a record or charging a credit-card). A PUT is unsafe but is idempotent (the above example can be retried in the event of a network failure or unacknowledged request and the end-result will be the same as a single call). A DELETE operation is unsafe but should also be idempotent.
Despite HTTP being the transport protocol for HTML, HTML only supports a subset of HTTP’s request methods (GET & POST) which often results in APIs that only support GET and POST through sheer inertia. When your API adopts the resource abstraction, where resources have stable identifiers, and your API uses the correct actions that correspond with the desired manipulations; you have a level 2 API on the Richardson Scale.
The most “enlightened” REST APIs in existence tend to only go this far down the scale. Although this level of design improves interoperability, we yet have more challenges to solve to make agentic systems a reality.
Semantics
At this point, we have an API that an intelligent agent can begin to use to manipulate resources in a standardized way. Unfortunately, our agents need to know more than protocol details, they need to understand what resource properties mean and how to change them. Our agents need to understand semantics which simply do not exist in json serializations, nor do they exist in a meaningful, machine-readable way in any API documentation.
JSON is simply a collection of decontextualized name/value pairs. The “name” portion of a JSON object is just a magic string designed to give the human programmers a clue or a reference for their programming efforts. This metadata must be received out-of-band and typically requires some amount of custom programming to implement.
There’s no reason this context cannot be communicated in-band, the only obstacles are mental and inertial.
In 1997, the W3C published a draft standard for a vendor-neutral system of metadata. This is known as the Resource Description Framework (RDF). What we learned in the early days of the web was that, if a document can be a resource, or an image can be a resource, or a row in a database table can be a resource; pretty much anything can be a resource. Remember, resources are just things that exist within a given domain that are important enough to give meaningful names to. The terms that identify given properties of a resource can easily be resources identified by a URI.
RDF (more commonly referred to as “linked data” or “linking data”) allows you to create or introduce a controlled vocabulary of terms with precise semantics.
Linked Data is a way to create a network of standards-based machine interpretable data across different documents and Web sites. It allows an application to start at one piece of Linked Data and follow embedded links to other pieces of Linked Data that are hosted on different sites across the Web.
Although RDF can be expressed in a variety of serializations, the most relevant (and familiar) for our purposes is JSON-LD. The JSON-LD specification (first published in 2010) is mature, production read, an official W3C Recommendation in the final stages of formal standardization.
From the W3C:
JSON-LD is a lightweight syntax to serialize Linked Data in JSON [RFC4627]. Its design allows existing JSON to be interpreted as Linked Data with minimal changes. JSON-LD is primarily intended to be a way to use Linked Data in Web-based programming environments, to build interoperable Web services, and to store Linked Data in JSON-based storage engines. Since JSON-LD is 100% compatible with JSON, the large number of JSON parsers and libraries available today can be reused. In addition to all the features JSON provides, JSON-LD introduces:
- a universal identifier mechanism for JSON objects via the use of IRIs [Internationalized Resource Identifier - a.k.a. a URI that supports Unicode],
- a way to disambiguate keys shared among different JSON documents by mapping them to IRIs via a context,
- a mechanism in which a value in a JSON object may refer to a JSON object on a different site on the Web,
- the ability to annotate strings with their language,
- a way to associate datatypes with values such as dates and times,
- and a facility to express one or more directed graphs, such as a social network, in a single document.
JSON-LD is designed to be usable directly as JSON, with no knowledge of RDF [RDF11-CONCEPTS]. It is also designed to be usable as RDF, if desired, for use with other Linked Data technologies…
Consider this JSON snippet:
{
...
"title": "doctor doctor"
...
}
In this document “title” can mean many things. It’s a magic string that might give clues but no reliable answers. Neither a human nor a language model can make a reliable inference based on the data alone. Feel free to guess what “title” means in this document before reading on…
An LLM might see the token for “doctor” near the token “title” and infer this to mean job title. Alternatively, it may determine “title” is an honorific in this instance (i.e. an earned title through education and/or professional qualification). As a human, you might see the duplication of “doctor” and speculate that something else is at play here. Title, in this case, refers to the title of a published creative work; “Doctor Doctor” the 1974 single from the band UFO’s third studio album.
This is just one of countless examples of semantic collisions, identical terms whose meaning changes as context changes. This is a pervasive problem that neither linguistics nor language models are prepared to solve. The fundamental problem is that semantics are entirely dependent on context; context that JSON cannot express, and AI cannot reliably infer.
This problem, however, is not new. German Philosopher and Mathematician, Gottlob Frege, attempted to understand the true complexity of language in his 1892 Paper [“On Sense and Reference.]”(https://youtu.be/sDlFaOn71n8) Those who have studied Domain Driven Design (DDD) will see parallels with the concept of a Ubiquitous Language, a “a common, rigorous language between developers and users”. An analysis of language within any nontrivial organization often reveals consistency boundaries; lines where meaning begins to change. These boundaries define our contexts and JSONLD allows us to navigate those contexts confidently.
DDD prescribes an anti-corruption layer to perform translation or conformity across contexts. In contrast, the RDF and Linked Data standards embrace what is known as “the nonunique naming assumption” which understands that, in reality, the same entity could be known by more than one name. The RDF/Linked Data world not only accepts the complex reality of language, it provides tools to operate contextually. For example, if JSON is just decontextualized name/value pairs, we can simply add the context. This is the heart of what JSON-LD gives us.
{
"@context":{
...
"title": {
"@id": "http://purl.org/dc/terms/title",
"@type": "http://www.w3.org/2000/01/rdf-schema#Literal"
}
...
}
...
"title": "Doctor Doctor",
...
}
This particular term, identified by the URI http://purl.org/dc/terms/title specifically means the title of a creative work (e.g. book, film, recording, magazine, etc.) as is part of a formal vocabulary that has existed for almost as long as the web. The @context maps the URI that identifies the term to the magic string in the JSON doc. Any client that understands JSON-LD can begin to understand the semantics of the payload. If the term is new to the client, it can dereference the URI to pull in more data that describes the term in a machine-readable RDF serialization. Alternatively, a human can type that url into a browser and see a webpage that describes the term and presents the term’s metadata in an HTML table.
What’s remarkable about backing the magic string “title” with a context that identifies its semantics is that it doesn’t matter what you call it. If your preferred term is AlbumTitle (https://example.com/MusicCatalog/Terms#albumTitle) while mine is simply title (http://purl.org/dc/terms/title) then, if you decide that those two terms mean the same thing then the whichever term that is appropriate for a given context can be used without issue.
The RDF model for metadata is surprisingly powerful. Once you define meaning, you can begin to define controlled vocabularies. With these vocabularies you can begin to define everything necessary to not only understand a JSON payload, but how to interact with it, validate it, and create new instances of it. For example, one of the first controlled vocabularies was the RDF Schema Language (RDFS) which contains the necessary classes and terms to describe a linked data vocabulary. By using RDFS & JSON-LD, your API can begin to include a wealth of in-band information necessary for agentic interaction.
The more you dig into JSONLD, the more you’ll begin to wonder why we this hasn’t been our default over the last 10-15 years (or you are likely wondering why this is the first time you’re hearing of it). Moreover, it’s conspicuous absence from the mainstream might lead one to suspect it is still ahead of its time since every language model has a knowledge cut-off in the past. Fortunately, most language models are fluent in JSON-LD.
One of the primary sources of training data for most language models is the common crawl a vast dataset that encompasses over 250+ Billion web pages spanning 18+ years. Currently around half of the indexed web contains embedded JSON-LD. This effort was championed by Google, Microsoft, Apple, Yahoo, Yandex, and others who were all trying to perform reliable data integration at massive scale from highly heterogenous data sources. This consortium of frenemies has collaborated to provide a foundational, general-purpose vocabulary for many common concepts on the web..
Beyond Semantics
We are beginning to assemble the building blocks of an API that an agent can understand and interact with, but RDF provides the tools to continue building on the stack of standards to make this vision a reality.
The RDF standard has continued to be augmented with other first-class vocabularies beyond RDFS. OWL, the Web Ontology Language, provides much richer tools for defining more complex semantics and relationships. OWL opens many doors to explainable reasoning and inferencing that is not currently possible with most AI approaches. Another notable first-class vocabulary is SHACL which provides a means to express and execute validation rules on data.
All that said, an agent not only needs to understand your data, but it must understand your API as well.
Journey to a Level 3 API
Around a decade ago, I made a sincere effort to truly understand REST. It wasn’t easy, most of the information I could find was flat out wrong. Moreover, since REST is so poorly understood most of what I could find was contradictory. I turned to well-respected tech giants for authoritative answers, but they were often just as wrong (and inconsistent) as the rest of us.
It took a couple of years, but I finally began to truly understand REST and its implications. I became an irritating RESTafarian. My “Well ACKSHUALLY…” comments echoed through conference corridors around the world. Fortunately, that chapter of my life was relatively short-lived.
Long story short, I learned the crux of the REST architectural style is HATEOAS (Hypermedia as the Engine of Application State). While most of the REST community argues over PUT vs POST, we completely ignore that it is HATEOAS (i.e. the hard part) that provides the answers.
HATEOAS can be a challenging concept to wrap your head around until you leave the context of APIs. Then it becomes remarkably simple. HATEOAS is how the web works. Point your browser to this blog and it will do a GET request to retrieve the current state of that resource. Within that response is a self-describing and semantically rich hypertext document, written in HTML (HyperText Markup Language) that contains hypermedia controls in the form of links to navigate the information space and forms to interact with the resources (affordances). The form, for example, contains everything your browser needs to know to perform a search. If I change how search works, your next visit to the site will contain updated hypermedia with new instructions on how to interact with the search. In short, a hypermedia resource not only gives the client everything it needs to understand the resource, it also gives the client everything it needs to be able to interact with the system.
If your API is hypermedia-driven, it is a level 3 API. Then–and only then–can you legitimately call your API a REST API.
If you want to understand HATEOAS, I recommend watching the first half of this talk I recorded last year.
In the second half of that talk, I begin to explore why there are so few (if any) level 3 REST APIs in the wild. I believe there are two reasons:
- Hypermedia has, historically, never really made sense for APIs.
- Most practitioners are not aware of hypermedia types suitable for APIs.
The big issue is (was) #1. Hypermedia has always been for people. APIs have always been for machines. For as long as APIs have existed, they have been designed for machine-to-machine interaction through preprogrammed and tightly-scripted mechanisms. It has never made sense to give an API client affordances at runtime because those typically have to be known at design-time. Consequently, changing those affordances would still likely break API clients.
The fact that hypermedia has only ever been useful to humans interacting with a software system rather than machines makes the second point moot. Until now. Suddenly, the idea of providing semantically rich and self-describing API endpoints is extremely valuable. Imagine an AI agent able to realize zero-shot API interactions with any arbitrary software system. This is entirely possible.
Hydra has entered the chat
In 2013, Markus Lanthaler published a paper entitled “Creating 3rd Generation Web APIs with Hydra” where he described “a novel approach to build hypermedia-driven Web APIs based on Linked Data technologies such as JSON-LD. We also present the result of implementing a first prototype featuring both a RESTful Web API and a generic API client.”
Basically, what Lanthaler figured out was if JSON-LD can unambiguously describe data, RDFS can unambiguously describe a vocabulary, etc.; why not create a vocabulary that precisely defines the API, endpoints, route patterns, paging, documentation, affordances; everything necessary to understand and interact with the API inside the payloads. In other words, exactly how HTML and the web works.
He went on to prove that if a client understands the linked data standards and the hydra vocabulary, a singe client can interact with any level 3 API that supports JSON-LD and hydra.
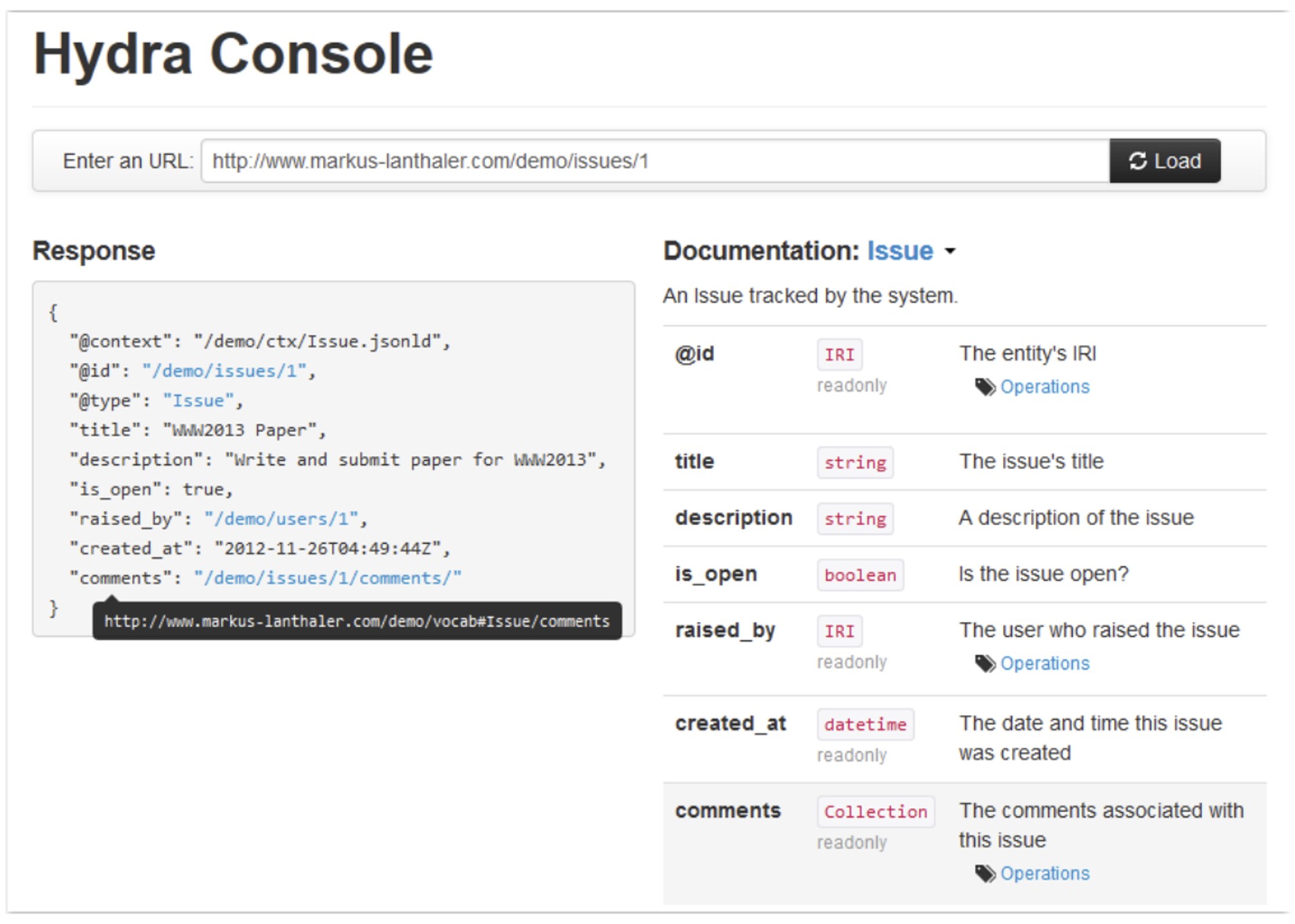
The recorded conference talk linked above also goes into a deep dive of Hydra if you’d like to learn more.
Putting it all together
In part we explored two incremental evolution approaches to building agentic systems along with the primary challenges currently holding us back. There is a lot of value in a web-driven approach, but bot restrictions, security concerns, and UI fragility hold us back. The API-driven approach is more appropriate for machine-to-machine interaction but lacks the richness of hypertext. The answer is in the intersection.
- Discovery - A Hydra API is fully self-describing requiring no out-of-band knowledge to interact with the system. This is the same reason you don’t need to download a browser plugin to go to a website you’ve never been to before.
- Semantics - Data payloads in either direction, API affordances, requests, responses, errors, and more can be consistently understood by an intelligent agent at runtime with JSON-LD, HTTP, and Hydra.
- Interface Fragility - The source of truth for how to query a collection of resources, or create a new resource is the API itself, not pre-programmed instructions. In this way a hypermedia-savvy agentic client can dynamically evolve as your system does
Mature REST is not new, it’s been old enough to drink for over a decade. The more nuanced details of REST and the Semantic Web have been overlooked for decades, but this is exactly the kind of universal interoperability of systems and data that Tim Berners-Lee and his band of merrymakers over at the W3C have been thinking about since the late 1980s. REST+JSON-LD+Hydra+SHACL is a mature and production-ready stack just waiting for a forward-thinking team to put into practice to enable true autonomous agents.
Tune in for Part III where we go through the logical architecture of such a system.