A Practical Path to AI Agentic Systems (Part I)


I’ve been designing and building data-driven & machine learning-enabled applications, on and off, for roughly 15 years. Although I was fortunate to have access to GPT3 about a year ahead of the mainstream, I was wholly unprepared for the wide-reaching impact of this technology. The introduction of ChatGPT in late 2022 brought into sharp focus just how impressive the current generation of large language models have become. The sheer breadth of zero-shot capabilities demonstrated by a single model has everyone’s minds racing. There is obviously immense power here, but how do we harness it to realize its true value and potential? That is the trillion-dollar question.
One of the most compelling visions for humanity’s next steps with AI is creating autonomous agents; AI systems that can do more than summarize text and provide plausible, information-shaped responses to our prompts. These are AI systems that can interact with other systems or the physical world. Although a great deal of R&D is underway as I write this, I’m shocked that one of the most promising solutions to the conundrum of how to achieve such agentic systems continues to fly under the radar…
Lateral Thinking with Withered Technology
I suspect the primary reason the approach I intend to introduce in this article series isn’t already being talked about is because the ideas aren’t new. In a world plagued with novelty bias and an obsessive pursuit of the next shiny-object we rob ourselves of both the opportunities presented by learning lessons from the past and the “lateral thinking with withered technology.”
“The genius behind this concept is that for product development, you’re better off picking a cheap-o technology (‘withered’) and using it in a new way (‘lateral’) rather than going for the predictable, cutting-edge next-step…
Most product concepts are the result of iterative evolution. They tend to be slightly thinner, faster or differently hued than their competition. You can see them coming a generation away. By contrast lateral products are bold and surprising because they tackle their category orthogonally.”
-Untamed Adam - Nintendo’s Little-Known Product Philosophy
Between 1997 and 2013, we completely solved many of the problems we currently face with agentic systems, but the solution did not appear to offer meaningful value in the context of its time. Consequently, it was ignored and subsequently forgotten.
What we must understand is not every idea from the past is obsolete. Not every idea from the past is old, some–and the ones most worth paying attention to–were simply ahead of their time. Those with the vision to look both forward and back are those who have vision to truly glimpse the future–and sometimes create it.
“Nothing is more powerful than an idea whose time has come.” -Victor Hugo
From Conversational Interfaces to AI Agents
My first introduction to natural language, conversational interfaces came in the mid-1990s. I was bored in my “Design/Technology” GCSE class. Consequently, while everyone occupied themselves with tedious busywork, I mostly played with the Acorn RISC PCs dotted along the perimeter of the classroom. Instead of focusing on my coursework I built a clone of ELIZA.
ELIZA is a very simple chatbot created to explore communication between humans and machines. It operated on rudimentary pattern-matching and substitution methodologies to create the illusion of understanding. Most commonly it would simply reflect back a rephrasing of inputs which led to the most popular ELIZA script, a Rogerian psychotherapist which mostly transformed statements into questions.
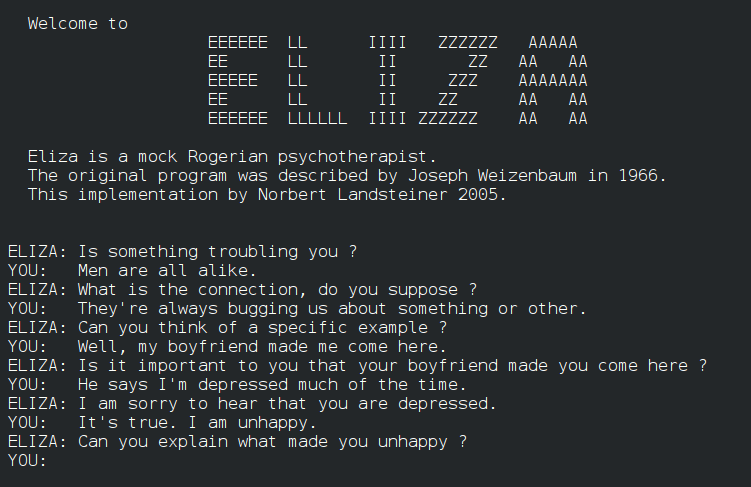
When I showed the results to my classmates, they were both impressed and quickly taken by the ELIZA Effect. I, in contrast, was unsatisfied.
My work moved on to developing my ELIZA clone into a general purpose chatbot that could carry on a much wider variety of conversations. I spent the next year working on this project to the dereliction of my coursework. Eventually my coursework was due (and represented 60% of my final grade) so I scrambled to compress two years of coursework into two weeks. Somehow, I managed to eke out a B and I kept playing with my chatbot.
Around the same time, I was regularly watching Star Trek TNG, and I was always impressed with how crew members could talk with the ship’s computer and it would not only talk back, it would perform the tasks they asked!
“Computer, run a level-four diagnostic on the warp core” -Geordi La Forge (probably)
I began to imagine upgrading my chatbot to perform tasks on my behalf, based on my natural language prompts.
Despite a great deal of work, my chat-powered agent could only perform tasks that I had pre-programmed. Moreover I could never truly enable my agent to take actions based on a broad enough syntax to be practical. All I had accomplished was the creation of a new “fuzzy” syntax for basic system commands (or, if you’re feeling generous, ZorkShell). Ultimately, I had neither the knowledge nor the computational horsepower to build such a system, but I never forgot that dream.
Fast-forward a quarter-century or so, and the encoder-decoder and transformer architectures allow radically improved prompt inference. The models can now “understand” (in a sense) what we are asking. Perhaps we are entering the age of AI agents.
The Rise (and fall) of the Rabbit R1
Following the AI gold rush precipitated by the release of ChatGPT, we were introduced to a number of agentic AI devices, including the Rabbit R1.
The Rabbit R1 was a device that promised to augment the chat capabilities of these models with their supposedly revolutionary Large Action Model (LAM). I wondered if this would make my silly sci-fi fantasies from the 1990s a reality, but as I read scathing review after scathing review, I quickly realized this was just a fancy GPT wrapper around the same basic system I built last century. In other words, despite improved natural-language inference, it could only execute a limited number pre-programmed tasks.
Investigation into this LAM revealed a handful of playwrite scripts designed to automate the browser in a very rigid way. This explained the limited number of “actions” and why the actions were so brittle.

Now, since the disastrous release of the R1, I’m told the product has gotten better (and we’re seeing progress from different software and hardware vendors). That said, the iterative evolution of the cutting edge is still fraught with problems.
When a company uses the term “agent,” they are intentionally trying to be deceitful, because the term “agent” means “autonomous AI that does stuff without you touching it.” The problem with this definition is that everybody has used it to refer to “a chatbot that can do some things while connected to a database, which is otherwise known as a chatbot.” -Edward Zitron
The Limitations of LLMs
Although LLMs demonstrate impressive and clever tricks, they are deeply flawed.
The first problem is that of hallucination. I once asked ChatGPT to generate some code for me and it promptly returned a copy-and-paste ready code-snippet for me. This was fantastic… except the code was invalid; the crux of the code was a call to a method that didn’t exist. You see, language models have no concept or understanding of the programming language (or any language). Instead, they rely on patterns observed in the training data. When a response is generated, the model iteratively looks for the next probable token based on the prompt and the output produced so far. In my case, the model hallucinated a statistically probable method. The model is not “thinking” and is not “understanding” anything. It’s all just spicy autocomplete.
We’ve managed to paper over the problems of hallucination through techniques such as Retrieval-Augmented Generation (RAG) where we perform more traditional information-retrieval processes to build a concrete context for a model to work from.
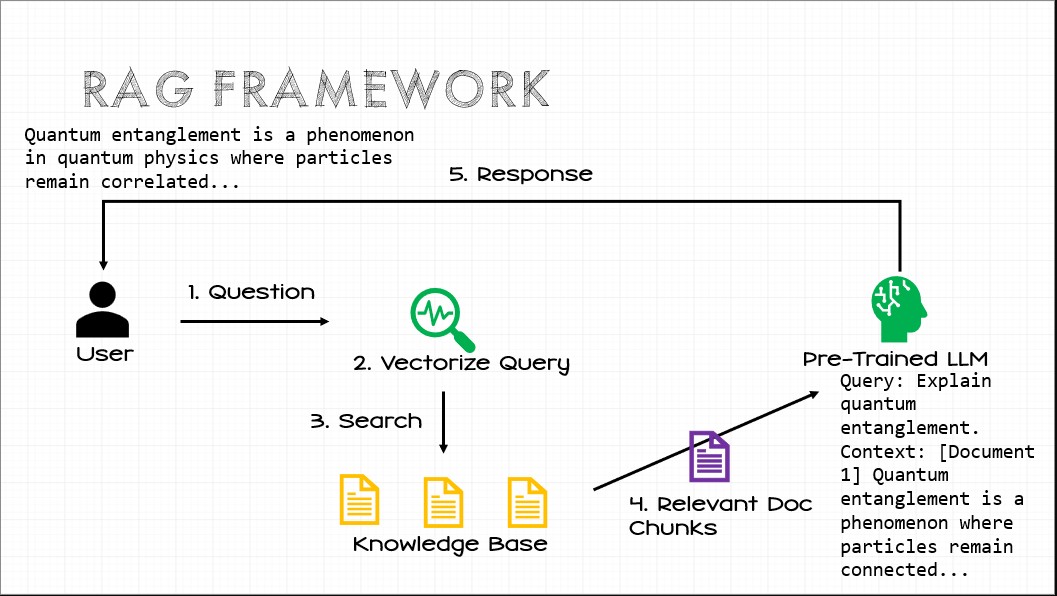
Give the AI Chrome?
This style of approach is driving at least one current iterative evolution approach towards agentic systems. Essentially this approach asks, “What if we just give the LLM a web browser and have it navigate a UI and figure out how to operate the app?”
There are a few problems with this. First many web apps are hostile to bots and introduce some measures to restrict use to humans. Second, between developer apathy towards accessibility and overcomplicated web development frameworks, it can be difficult for an AI-driven browser to function reliably. There is also the danger of prompt injection.
It remains alarmingly easy to highjack a language-model’s train-of-thought by introducing language that fundamentally changes the instructions. The ever-widening context-windows available in the most cutting-edge models only amplify this problem. Although both bespoke and off-the-shelf guardrails exist to attempt to detect prompt injection, we continue to come up with novel approaches for jailbreaking constrained models to behave in ways they are not supposed to.
What would happen if a bad actor injected a sufficiently well-crafted prompt into the page content? Could that enable the actor to hijack the agent in dangerous ways? Probably, and it’s worth being concerned about.
We also have to contend with the fact that AI only possesses limited contextual understanding of what it is looking at. Recent high-profile faceplants observed in Google’s AI results have advised users to add glue to pizza sauce (because the model has no concept of a shitpost on reddit), to eat small rocks daily (because the model has no concept of a satirical website), and even advising men to iron their scrotum (because the model incorrectly conflated wrinkles in fabric with wrinkles in skin).
Can we trust a model to find and interact with the right site, or could it find a convincing fake site to enter your credentials into? It seems like we’re back to creating pre-defined behaviors. This is especially true as we get to the problem of resource discovery.
Generally for any software system to interact with another software system, there is some amount of out-of-band information the client must possess. This typically includes URLs, data structures, functionality, validation rules, etc.
Truth be told, an AI driving a web browser (with a limited amount of out-of-band information) could probably navigate a web application and fumble around until it found the correct screen and functionality to invoke. This remains slow and unreliable.
There’s also the issue of data semantics (the meaning of terms or their relationships). A model could probably infer a statistically plausible set of semantics for a form, but these remain probabilistic guesses. Semantics are fairly easy for humans to get right, and even easier for language models to get wrong.
What About Giving the Model CURL?
We can sidestep some of the problems inherent to giving a model access to a web ap by instead having it interact directly with the API. Asking a language model to present information as JSON is not uncommon, and this is a useful way to connect language models to classical code. This does, however, significantly increase the amount of out-of-band information necessary to interact with the system, which prevents agents from being truly autonomous. We still need to pre-program behavior, API docs, JSON schemas, semantics, etc. for every application our agent might interact with.
There is also the problem of semantics. Working directly with an API also removes much of the context necessary for a model to naturally infer semantics. Instead, it is only working with decontextualized name/value pairs. The English language is astonishingly vague, and many words are overloaded. Language models frequently fail to accurately determine the correct semantics with so little context. We also still run the risk of the model hallucinating an API endpoint or a payload simply because it is statistically likely to exist.
Another glaring issue is the way we currently build APIs. The vast majority of JSON APIs offer an inconsistent interface. Often these are a mix of narrow and/or overloaded RPC calls. Paging and filtering mechanisms are often inconsistent, it is not always clear which API endpoints have side effects, which endpoints are idempotent, etc. As things stand, without a lot of custom programming and a whole pipeline of guardrails, direct API access is even riskier than an agent driving a web browser.
MCP: A Structured Alternative to Raw API Access
Handing an LLM raw API access and expecting it to “figure things out” is, at best, an optimistic experiment and, at worst, an exercise in watching an agent fumble through trial-and-error API calls. Hard-coding API calls works for simple use cases but breaks down as soon as APIs evolve, authentication schemes change, or an unexpected response derails the model’s assumptions.
Traditional RPC interfaces (like JSON-RPC and gRPC) promise a clean method-call abstraction, but in reality, they suffer from the same problem: they expose operations without meaning. The API might say getCustomerBalance, but the model has no way of knowing what “balance” actually represents—available credit? Outstanding debt? Cash on hand? Even if an API is well-documented, that documentation exists outside the execution context, forcing the model to blindly associate calls with natural language descriptions that may be incomplete, misleading, or ambiguous.
This is where Model Context Protocol (MCP) enters the picture. Instead of an ad hoc API integration, MCP provides a structured way for models to discover, describe, and interact with external systems. It acts as a semantic bridge, exposing capabilities explicitly via machine-readable metadata. Think of it as an API index card that not only lists available operations but also provides type definitions, valid parameters, and descriptions of expected side effects. Instead of an agent hard-coding POST /submitInvoice, MCP tells it, “Here’s a structured action called SubmitInvoice, it requires an InvoiceID and Amount, and upon success, it returns a TransactionID that you can use to track payment.”
MCP solves three major problems with traditional API access:
- Capability Discovery: No more hard-coded API lists—agents dynamically discover what’s possible at runtime.
- Schema Awareness: Models get structured descriptions of expected inputs and outputs, reducing hallucination and misinterpretation.
- Context-Rich Execution: API calls are described in a way that helps an agent reason about them instead of guessing based on function names.
But MCP is not a silver bullet. It improves how models interact with APIs, but it doesn’t fully solve the problem of understanding why an action should be taken or how different API calls relate to one another in a broader workflow. There’s still work to do in making APIs self-describing at a deeper level, enabling agents to chain calls intelligently rather than invoking them in isolation.
For now, MCP is a significant step up from traditional API integration, moving us toward agentic systems that interact with external data in structured, predictable ways. But without deeper semantic modeling, agents remain capable but contextually naive—able to call functions but not always able to reason about their broader implications.
Summary of Challenges
The challenge that anyone who has spent much time playing with language models is most familiar with is hallucinations. However, given a large part of the raison d’être of these models is generating novel responses to prompts, this phenomenon occupies a strange feature-bug duality that we have to contend with. Their behavior is, by design, nondeterministic. At the same time, these modes have demonstrated themselves the most capable AI models humanity has yet created. Their broad utility and adaptability have led many to believe they offer an adequate foundation to build agentic ai systems.
Although techniques exist to manage hallucinations, the obvious incremental evolution approaches are, by themselves, leaving much to be desired.
In any event, beyond hallucinations, we must identify a path to deal with the following:
Discovery
We need a reliable mechanism for a given model to figure out what options exist in the target application the agent might deal with. From a web-driven approach, assuming bot restrictions are not in place, the model needs to either be able to discover functionality within the web app, or some amount of fine-tuning or custom programming must exist to make these details directly actionable.
Arguably, the most appropriate path for machine-to-machine interaction is via an API yet both approaches are currently being explored. An API-driven approach eliminates the challenges of bot restrictions. APIs built using modern tools and frameworks often produce OpenAPI Specification (OAS) documentation which can aid in discovery by, at a minimum, enumerating endpoints and briefly describing their purpose however a traditional API interface is positively anemic when compared with the richness of a web UI.
Consider an API that expects the following JSON payload:
{
...
EventName: ,
EventDate: ,
VenueAddress: ,
NumberOfGuests: ,
...
}
A language model could easily make reasonable (but unreliable) inferences around types or meaning. A more uniform approach such as MCP will include JSON Schema, but this is syntactic rather than semantic.
Contrast this with the following HTML snippet:
<input type="text" name="EventName" required />
<input type="date" name="EventDate" required />
<textarea name="VenueAddress"></textarea>
<input type="number" name="NumberOfGuests" min="10" max="5000" />
The form interface introduces an additional dimension of metadata as well as a wealth of context from the surrounding UI elements. As we discussed, while the web UI introduces some benefits, it also opens up new risks in the form of novel prompt-injection attacks. The API-driven approach mitigates this risk significantly.
We can provide an agent with better API documentation with more precisely designed schemas to move in the direction of parity (part of the current motivations for MCP), however these artifacts overlook a more critical gap.
Semantics
Beyond type validation, the agent must be able to accurately and reliably infer the semantics of each attribute in the API payload. API interfaces and responses lack the rich context of a UI, making it harder for LLMs to infer meaning accurately. JSON schemas and the like do not currently address this issue.
Out-of-Band Information Needs
Succeeding with an API-driven approach with APIs as we design and build them now requires a significant amount of out-of-band information; information that is a pre-requisite of interacting with the system. Much of this will need to be provided at design time or fine-tuning-time which will significantly limit the agency and autonomy of the agent.
Interface Fragility
LLMs lack real-time learning and adaptation; they rely on pre-trained knowledge and retrieval-based augmentation. One of the conveniences of a web interface is that the HTML representation of a web page includes instructions for navigating and interacting with the system in the form of hypermedia controls (a and form tags). If a breaking back-end change is introduced, the HTML is modified. Likewise, if new functionality is introduced into the app, the HTML is modified accordingly to surface that functionality. This provides some level of dynamic adaptability.
Contrast this with the API-driven approach, where breaking changes typically break the client which requires client code modification. Due to the need for out-of-band information, the agent must either rely on outdated API specifications or it must wait for the new functionality to be programmatically enabled on the client. Even stable APIs often have inconsistent interfaces, which will only compound the problems.
We must also figure out how to contend with the reality that LLMs do not inherently understand error handling or edge cases, making automated interactions unreliable.
Ultimately, an agentic system that must infer interaction patterns on every request is likely too slow for practical applications.
While LLMs and agentic systems hold promise, their use in autonomous decision-making and system interaction when following iterative evolution remains risky. As magical as LLMs sometimes appear to be, the magical thinking that is so pervasive in the AI sphere won’t get us where we want to go. There are fundamental problems that must be addressed to pave a path forward to agentic systems with current technology. Yet, the incremental evolution approaches only provide half-solutions.
So, What’s the Answer?
That, dear reader, will have to wait for part II of this series. We will tackle the major problems one-by-one to pave a pragmatic path towards truly autonomous AI agents.