Abstract Style: N-Tier

So far in this series on abstract styles we have only looked at monolithic abstract styles and a handful of defining constraints. In reality, however, much–in not most–of the systems we will design as architects will involve some kind of network component. Although many implementations of the layered monolith or modular monolith may be extended through the addition of the client-server constraint (and, typically, some type of API constraint) the next several posts will focus on abstract styles that are, at their core, natively distributed. We will start by examining the N-tier architecture.
This post is part of a series on Tailor-Made Software Architecture, a set of concepts, tools, models, and practices to improve fit and reduce uncertainty in the field of software architecture. Concepts are introduced sequentially and build upon one another. Think of this series as a serially published leanpub architecture book. If you find these ideas useful and want to dive deeper, join me for Next Level Software Architecture Training in Santa Clara, CA March 4-6th for an immersive, live, interactive, hands-on three-day software architecture masterclass.
Introducing the N-Tier Architecture Pattern
Although older and less exciting than more recent distributed system patterns, the n-tier architecture maintains a meaningful share of distributed system architectures, offering a path of evolution, scalability for existing, technically partitioned client-sever layered monoliths. The n-tier architecture also builds on widely familiar paradigms, offering a reduced learning curve for developers needing to adopt a more distributed architecture. It offers a meaningful alternative to domain-partitioned architectures where the necessary organizational work of Domain-Driven-Design (DDD) and the potential re-orgs that may entail are currently out of reach or otherwise impractical for the organization shipping the software.
This pattern builds on the structure and ideas of a layered monolith and decomposing the logical layers of the monolith into independently deployable/scalable horizontal slices. A horizontal slice could also, in theory, be vertically sliced (but finding the optimal boundary can be tricky without first identifying the natural seams in the domains.) One of the earliest formal definitions of this pattern was published by Wayne Eckerson in 1995 in his publication “Three Tier Client/Server Architecture: Achieving Scalability, Performance, and Efficiency in Client/Server Applications.” Within a few years it became clear that, perhaps, three tiers might be too restrictive/prescriptive and many implementations varied the number of potential layers which afforded the architect more control over component granularity, which in-turn, affects scalability, elasticity, deployability, and agility. Notably, the generalized “n-tier” architecture is not prescriptive on the number of tiers (the size of n). N could, in theory, be as few as one (i.e. a monolith) or two (i.e. a client-server monolith). This creates some semantic ambiguity so, for our purposes, we will assume three or more tiers.
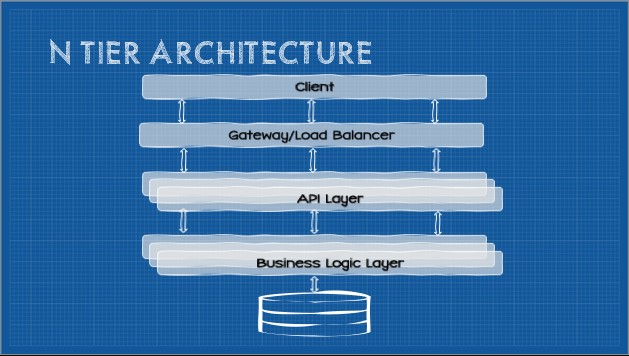
From the top-down, the first tier is the client. This could be a fat-client, a Single-Page Application (SPA) served as static files from a CDN or web server, a PWA, a Mobile App, or any number of others. The client communicates across the network to the server through some kind of API layer. Typically the responsibility of this layer is marshalling incoming requests, handling client authentication, output caching (if an optional cache-constraint is applied), rate-limiting (although it may make sense to delegate some of these to an additional API gateway layer between the client and the API layers). The API layer is generally fairly thin and lightweight which affords faster start times for elasticity.
The next tier is typically some kind of business-logic layer. Again, as a separate and independently deployable component, in theory this component may be independently deployed and scaled (although another intermediary load-balancing layer may be required).
Finally there is a persistence layer. This could be as simple as a database server, or there may be a persistence layer in between.
There is no formal guidance around how many layers are needed, but a general rule of thumb is “only as few as are necessary.” Every hop introduces latency and it is easy to accidentally implement a distributed sinkhole antipattern.
The Sinkhole Antipattern: A layered architecture where each layer is merely passing data up and down through all the layers with no modification.
Layers need not simply be horizontal slices of an existing monolith. Layers may also provide a modern and stable facade encapsulating legacy systems, improving overall interoperability and abstraction.
Core Constraints
The overall capabilities of this abstract style can be depicted as follows:
These capabilities are induced by a number of core constraints as follows:
- Coarse-Grained Components
- Independent Deployability
- Technical Partitioning
- Shared Database
- Separation of Concerns
- Client-Server
- Layered System
- API communication
There are many strategies and approaches to API communication, each with various strengths, weaknesses, and trade-offs. Given most organizations gravitate towards this particular pattern due to familiar conventions and low learning-curve, we will presume a RPC-style API owing to its similar familiarity and low learning curve.
Constraint: Coarse-Grained Components
This constraint states that the overall system is decomposed into coarse-grained components. Precise granularity is not prescribed, but generally a single coarse-grained component may span multiple domains or busines functions.
Fault-tolerance (+3)
Although hampered somewhat by the larger granularity, decomposed components are generally lighter-weight and offer reduced start times eliciting improved elasticity compared to monolithic systems.
Performance (+3)
Coarse-grained components generally require fewer network calls as many common functions are co-located locally within the component boundaries reducing latency and improving performance.
Elasticity (+2)
Although hampered by the larger granularity, decomposed components are generally lighter-weight and offer reduced start times eliciting improved elasticity compared to monolithic systems.
Testability (+2)
Breaking an application into smaller components reduces the total testing scope. Furthermore, generally components have well-defined API contracts which abstract implementation reducing complexity of integration testing across teams.
Deployability (+1.5)
A system decomposed into compents begins to pave the way for smaller-scoped deployments and partial deployments of the system. Deployments scoped to components, even coarse-grained components, reduces deployment risk and simplifies pipelines.
Scalability (+1.5)
Even at a coarse granularity, components may be individually scaled increasing total available compute where it is most needed.
Agility (+1)
Decomposing a system into independent components of any granularity with thoughtful module boundaries has the potential to improve business agility. Components may be independently evolved and deployed with reduced overall testing scope.
Evolvability (+1)
Decomposition into components enables different parts of the system to evolve at different rates. Adding or changing functionality may often be scoped to a single component. Depending on other factors (module boundaries, coupling, system structure, etc) some changes may span multiple components, hence only a modest improvement on this capability
Integration (+1)
Decomposing as system into components is a forcing function for integration. Components must be able to communicate and work together, which generally improves this capability at the system level.
Interoperability (+1)
Likewise system decomposition is generally a forcing function to decouple components, modestly enabling interoperability across components.
Workflow (+1)
Coarse-grained components typically contain many modules and functions which modestly improve the ability for a module to orchestrate workflow behavior within a module boundary.
Configurability (+0.5)
Decomposing a system allows components to be individually configured and each component may utilize different framework versions, runtimes, languages, or platforms.
Cost (+0.5)
Coarse granularity of components reduces total cost of ownership in terms of development time, change time, and bandwidth costs but is offset by design, development, and compute overhead involved in a distributed system.
Simplicity (-1)
Decomposing a system into independent components of any granularity introduces additional design and operational complexity.
Constraint: Independent Deployability
This constraint states that the system as a whole need not be delpoyed at one time. Any individual component must be deployable in isolation. This consrtaint cannot co-exist with the monolithic deployment granularity constraint.
Agility (+1.5)
Independent deployability requires some rules around modularity. Clean and stable module boundaries must, therefore, exist (be it in the form of plug-in architecture, event processors connect by async processing channels, independant services, or service layers). These module boundaries in place, combined with independent build and deployment pipelines, significantly improve overall agility. To respond to change, a module can be create or modified and deployed with low overall risk to the rest of the system. Change scope remains constrained and deployment risk reduced increasing overall delivery velocity.
Deployability (+1)
In the same vein of Agility, overall deployability is improved.
Elasticity (+1)
Independent deployability improves component independence and improves elasticity.
Evolvability (+1)
The independant deployability constraint enables different parts of the system to evolve at different rates. Adding or changing functionality is often as simple as a single, scoped, focused deployment.
Scalability (+1)
Independent deployability improves component independence and improves scalability.
Cost (+0.5)
The capability of surgically-precise deployments reduces the overall total cost of ownership of the system. This capability is limited, however, as independant deployability typically requires additional investment in build and deployment infrastructure which incurs a cost penalty. In aggregate, the trade-offs of this constraint are a small net positive.
Simplicity (+0.5)
Although development and management of independant build and deployment pipelines introduce complexity and require some specialized skills, once this infrastructure is in place, the system as a whole is generally easier to maintain and modify. Again, in aggregate, the trade-offs evaluate to a modest net positive.
Constraint: Technical Partitioning
This constraint introduces some structure in terms of how components of the system are organized. In this case components are grouped by their technical categories. As the depiction of the abstract style indicates, usually these are along the line of UI/Presentation, Business logic, persistence, and database but this constraint can apply to both monolithic and distributed topologies.
Generally layers are consider either open or closed. Closed layers abstract any layers below the closed layer - meaning they must act as an intermediary. Open layers are free to be bypassed when it makes sense (the sinkhole antipattern defines a scenario where the layers don’t apply any meaningful changes or validation on the data as it passes through a layer).
Cost (+2)
This constraint introduces some structure in terms of how components of the system are organized. In this case components are grouped by their technical categories. As the depiction of the abstract style indicates, usually these are along the line of UI/Presentation, Business logic, persistence, and database but this constraint can apply to both monolithic and distributed topologies.
Generally layers are consider either open or closed. Closed layers abstract any layers below the closed layer - meaning they must act as an intermediary. Open layers are free to be bypassed when it makes sense (the sinkhole antipattern defines a scenario where the layers don’t apply any meaningful changes or validation on the data as it passes through a layer).
Testability (+0.5)
Because this constraint add some structure to our software components, testing scope becomes better defined as do interfaces between layers.
Abstraction (+0.5)
Because one layer must interact with another, often this results in better interfaces and abstractions being put in place. As a result, generally this constraint slightly improves abstraction within the system.
Deployability (-1)
Deployability is degraded here, whether this constraint is applied to a monolithic or distributed technically partitioned system. Generally any single change requires modifications to all layers which increases testing and regression-testing scope and reduces velocity while increasing deployment risk.
Configability (-2)
Technical partitioning might introduce tight coupling between different parts of the application. This can make it difficult to change or configure one part without affecting others.
Evolvability (-2)
The large change scope, reduced deployment velocity, and increased change risk also adversely affects evolvability. The risk surface area is much larger than in domain-partitioned systems.
Constraint: Shared Database
This constraint states that the entire application utilizes a common database. While this is often a default of some abstract styles and patterns, it still strengthens and weakens capabilities and should be explicitly noted.
Cost (+1.5)
Generally sharing a single, shared database reduces licensing costs, hosting costs, and reduces development costs. Generally this also reduces data storage redundancy as there is much less need to replicate data to be visible to other application components.
Simplicity (+1)
Administration is simplified by virtue of having a single database to manage. Design is also simplified as all data modeling can be done at the application level rather than domain level.
Deployability (+0.5)
Deployment is generally straightforward as changes to a single database have reduced coordination costs. The improvement is modest, however, as DB changes at this scale can affect availability and introduce risk if schema that other components rely on change.
Configability (-0.5)
Configurability is reduced as any changes must be applied system-wide. A one-size-fits-all approach is generally required under this constraint.
Fault-tolerance (-0.5)
A single database becomes a single point-of-failure. Although most database management systems bring high-availability configuration options, if one database (the only database) is unavailable, the entire system is unavailable.
Scalability (-0.5)
Databases are notoriously difficult to scale. Multiple databases responsible for different parts of the data provide some level of parallelism and increase total capacity, a single database may be limited to scaling up.
Agility (-1)
Database changes potentially require coordinating with all teams and must be regression tested across all components. It can be very difficult to tell which teams are using various tables. Consequently, any change introduces risk which reduces change velocity.
Evolvability (-1)
The high coordination cost and testing scope also degrades evolvability.
Elasticity (-2.5)
As a single, shared resource, the system as a whole becomes less elastic because there is a ceiling to the single database’s capacity.
Constraint: Separation of Concerns
This constraint further narrows the technical partitioning constraint by being more prescriptive around how layer boundaries and modularity are defined. This constraint defines that code is not simply defined by technical area, but also logical concern.
Cost (+2)
Development and maintenance costs are reduced by adding this level of modularity to code. Developers may develop deep domain expertise in business logic (or subset of the business logic) which further reduces cost.
Testability (+1)
This constraint further reduces testing scope for any given change.
Agility (+1)
Agility is improved as the code generally has better boundaries, reduced testing scope, and potentially change scope.
Simplicity (+1)
This constraint generally improves simplicity of development and maintenance of the code. It is well-defined way to develop software, and this constraint improves understandability of the system components as well.
Evolvability (+0.5)
Evolvability is slightly improved as a consequence of the factors detailed above.
Constraint: Client-Server
This constraint separates client concerns from backend and data storage concerns.
Evolvability (+1.5)
By separating client concerns from server concerns, both the client and the server may evolve independantly. Furthermore, evolvability in the form of portability is incuded should multiple client implementations be requires (e.g. mobile platform specific clients)
Workflow (+1)
The workflow capability is modestly improved as a client may orchestrate some workflows.
Agility (+0.5)
The independent evolvability of the client and server induce a modest amount of agility. Client-server coupling generally limit this and often coordinated updates are required.
Configurability (+0.5)
Although limited in scope, clients may store user-specific or client-specific configuration independently from the rest of the system.
Deployability (+0.5)
Client and server may be deployed indepentently. Client-server coupling generally limit this and often coordinated updates are required hence this is only a modest improvement.
Elasticity (+0.5)
Decoupling client and server introduces some elasticity capability.
Scalability (+0.5)
Decoupling client and server allows improved independent scalability
Simplicity (+0.5)
The client/server separation of concerns slightly improves overall system simplicity.
Testability (+0.5)
The client/server separation of concerns reduces some testing scopes slightly improving overall testability.
Cost (-0.5)
This constraint slightly increases development, operational, and delpoyment costs.
Performance (-0.5)
Although separating client and server increase total available compute, this is typically offset by this constraint introducing network latency and overhead to most operations. Separating the client and server slightly reduces overall performance of the system.
Fault-tolerance (-1.5)
Typically both the client and the server must be available for normal functioning of a client-server system as well as an available network connection. This dependency reduces the overall fault-tolerance of the system (although this may be improved through additional constraints)
Constraint: Layred System
This constraint allows the overall architecture to be composed of multiple hierarchical layers. Often these are "closed" layers, constraining component behavior such that each component typically cannot "see" beyond the immediate layer. "Open" layers, in contrast, may be bypassed.
Abstraction (+2)
Layers, particularly "closed" layers, improve abstraction as a layer can be used to encapsulate legacy services and to protect new services from legacy clients. A layer facade to a legacy system, or an API layer provides some degree of abstraction within the system.
Evolvability (+2)
Layers may often be evolved indpendently (depending on overall coupling).
Simplicity (+1)
"Closed" layers restrict knowledge of the system to a single layer which limits overall system complexity.
Agility (+0.5)
The ability to abstract legacy systems combined with the innate composibility of layers slightly improve overall agility
Deployability (+0.5)
Decomposing a system into layered components with abstractions in the form of APIs or facades enable each layer to be independently deployed, slightly improving overall deployablity of the system.
Fault-tolerance (+0.5)
Separate layers may modestly improve fault-tolerance when deployed in a high-availablity fashioned.
Interoperability (+0.5)
This constraints potential for component abstraction and encapsulation operates as a forcing function towards improved interoperability. The gain from this constraint is modest but improved by additional constraints that ensure reduced coupling.
Testability (-1)
Although each layer introduces reduced testing scope, end-to-end testing of the system is often required and more difficult under this constraint. Furthermore, layers encapsulating legacy or external systems may be more difficult to test in isolation.
Performance (-1.5)
A disadvantage of layered systems is that they add overhead and latency to the processing of data and communication between layers, reducing performance.
Cost (-2.5)
Decomposing the system into layers increases operational costs requiring more compute instances for each layer and potentially introducing bandwidth costs.
Constraint: RPC-API
This constraint states that network communication between components take place through an remote-procedure-call (RPC) application programming interface (API)
Configurability (+1.5)
An API provides configurability through versioned contracts, the potential for more fine-grained control over signatures and payloads, and potentially content-negotiation.
Fault-tolerance (+1)
Networked API calls enable real-time routing to API endpoints. Such calls may often be load balanced and load-balancers may be aware of API instance health. When API interactions are semantically safe and/or idempotent, clients are free to retry failed requests. RPC APIs may lack standard response codes and clients may not know which requests are idempotent hampering failure recovery of some requests.
Integration (+1)
APIs provide a well-defined interface for component integration.
Interoperability (+1)
APIs provide a well-defined interface for component interoperability.
Cost (+0.5)
APIs, even RPC APIs (which are often tightly coupled) standardize on an interface which reduces development and maintenance costs.
Elasticity (+0.5)
Networked API calls may be routed to multiple available endpoints improving potential elasticity.
Performance (+0.5)
RPC endpoints are generally highly specific which enables some optimizations. Although coupling is often increased as a trade-off.
Scalability (+0.5)
Network APIs improve overall system scalability slightly.
Abstraction (-0.5)
The highly-specific nature of RPC endpoints reduces API abstraction.
Deployability (-0.5)
The highly-coupled nature of RPC endpoints often require coordinated changes reducing overall deployability.
Evolvability (-0.5)
The highly-coupled nature of RPC endpoints make changes more difficult.
Agility (-1)
The difficult of changing APIs without frequent client coordination reduces overall agility.
Summary
This pattern offers a path to improved scalability, elasticity, and evolvability without sacrificing too much cost overhead and complexity for organizations where domain-partitioned patterns are not a good fit or who wish to scale their legacy client-server monolith. Styles derived from this pattern may be adequate for a system’s needs, but this approach may be a stepping stone towards a future architectural state.