Abstract Style: Microkernel

Agility is a term that is typically poorly-defined–and often overloaded–in many business circles. Yet the underlying capability remains highly sought-after. Agility can be broadly defined as the ability of the business to adapt and respond to change. Agility is desirable because change is inevitable, and comes in a number of forms. With the progression of technology, from digital computers to personal computers, to the internet, to the web, to the mobile web, and beyond; the rate of change is only increasing. Businesses unable to keep pace will be disrupted, and we see this almost daily. We also cannot escape the fact that software runs almost every business. While there is a near infinite number of ways to write code to ship a set of features, software systems that are rigid and difficult to change will continue to constrain business agility. In short, if our software is not agile, the businesses it powers won’t be either.
As we have discussed in previous posts in this series, conventional wisdom is that monolithic architectures might offer low cost and high simplicity, but aren’t capable of meaningful agility. Through careful combination of key architectural constraints, however, architecture can yield monolithic systems that balance agility and simplicity. The goal of architecture is not to provide “a lot” (undefinable) of a given capability, but a minimum of “enough” (driven by business needs). To this end, we introduce another abstract architectural style, the Microkernel Architecture Pattern.
This post is part of a series on Tailor-Made Software Architecture, a set of concepts, tools, models, and practices to improve fit and reduce uncertainty in the field of software architecture. Concepts are introduced sequentially and build upon one another. Think of this series as a serially published leanpub architecture book. If you find these ideas useful and want to dive deeper, join me for Next Level Software Architecture Training in Santa Clara, CA March 4-6th for an immersive, live, interactive, hands-on three-day software architecture masterclass.
Introducing the Microkernel Architecture Pattern
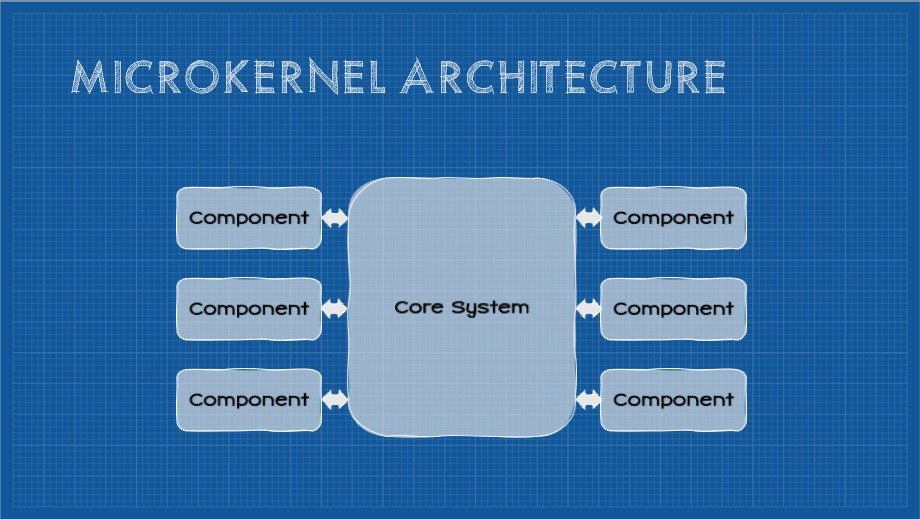
This pattern, sometimes referred to as the “plugin” architecture, applies constraints affecting the overall modularity of the application and builds on the concept of a microkernel from computer science. At the center of the pattern is the core system. In both computer science, and in this pattern, the core-system microkernel is the near-minimum amount of code necessary to implement the system. Additional functionality is provided in the form of external plugins. This approach isolates a codebase with low code volatility from “plugin” modules that typically have much higher volatility. Plugins can be added, removed, and swapped at runtime without requiring a redeployment of the core system and the nature of this architecture dramatically reduces impact from changes in plugin modules. As a consequence, plugin modules can be quickly developed that extend the core system and, at runtime, plugin modules can be added in various combinations and configurations to build arbitrary collections of functionality.
To see this pattern in action, one need only look as far as Visual Studio Code (the text editor I am writing this in). The core system provides basic functionality (primarily a text editor) and the functionality is extended by installing plugins. As an authoring tool, the core system isn’t especially powerful. If I add plugins introducing spell-checking capabilities, markdown support, git support, and terminal support (among others), suddenly I have a powerful environment that provides the tools and capabilities I need. Likewise I perform software development, data modeling, and even personal knowledge management using this tool, all enabled by additional plugins. Syntax support for a new language is as simple as another plugin. For a time, I extended VS Code in such a way that I could turn a collection of markdown documents into a powerful personal knowledge graph (essentially reproducing Roam Research with this stable core system) - all through a handful of plugins. As you see, the Microkernel Architecture Pattern is highly configurable. Any instance of the core system is free to select the set of plugins optimal for the given use-case. The instance also typically controls its update frequency improving overall configurability.
If a given implementation of this pattern utilizes storage, the storage mechanism is typically shared. VS Code utilizes the filesystem for persistence, but another example of this pattern is WordPress which allows plugins to not only create database objects (tables, indexes, views, etc.) in a single shared database, but the shared nature of that resource also means a plugin has access to other tables in the system.
Although the microkernel has a monolithic deployment granularity, the plugin approach enables new features and functionality to be added without redeploying the core system. Consequently the system can easily be extended in unforeseen ways, considerably improving agility, adaptability, extensibility, and evolvability. To achieve this, the core system exposes a uniform interface that defines both plugin entry-points and an API for plugins to interact with the core system (and, potentially, each other). Given plugins are constrained in their interaction with the core system, the application as a whole becomes more fault-tolerant. A malfunctioning plugin rarely takes down the entire system (often the core system will simply disable a problematic plugin).
The Microkernel Architecture also demonstrates some improvement in workflow capabilities. A plugin could act as an orchestrator, interacting with other interchangeable plugins, to achieve a workflow. There are trade-offs to this approach, but it’s worth noting.
These benefits, of course, come at a trade-off. Care and forethought must go into the specification of the uniform interface. The API must be reasonably stable (or backwards compatible) as combinations of plugins and versions can’t be known at design-time. Testability can be challenging as any number of plugins and configurations may exist at runtime. There typically must also be some kind of discoverability of available plugins, so in addition to developing the core system a plugin registry must be made available.
It seems that, generally, this pattern is best suited for software products that are stored and run locally (e.g. VS Code) however broader applications should not be overlooked. Many SaaS applications use this approach to make their platform configurable and extensible (both by the vendor and third parties). NetKernel is an example of this architecture (with additional constraints) implemented as a potentially massively distributed system.
All together, the core constraints of the Microkernel Architecture Pattern produce a set of capabilities that look like this:
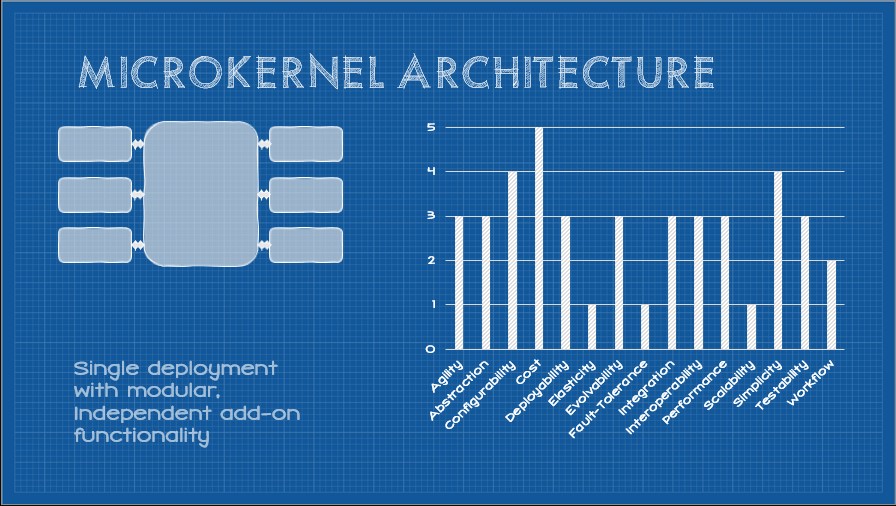
These capabilities are driven by a set of core constraints which are:
- Monolithic Build Artifact
- Independent Deployability
- Shared Database
- Separation of Concerns
- plugin Architecture
- Uniform Interface
In the following sections, we’ll examine each constraint and how it elicits certain capabilities while weakening others.
Constraint: Monolithic Build Artifact
As the title “monolith” (mono - single, lith - stone) suggests, the system is compiled into a single binary artifact. This constraint, like every constraint we will introduce in this series, introduces a set of trade-offs. Let’s start by looking at capabilities that are induced by this constraint.

Simplicity (+2)
If an entire system resides within a single binary, we avoid the challenges that distributed systems face. These types of systems avoid an entire category of complexity that distributed systems introduce. The challenges that distributed systems introduce are best exemplified by the fallacies of distributed computing. In summary, the fallacies are:
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn’t change
- Transport cost is zero
- The network is homogeneous
Basically, the fallacies describe the complexities that emerge when a system becomes distributed. In short, there is a lot less that developers have to worry about with a monolith.
In addition, the build process is generally much simpler. It can be as simple as performing a build in an IDE.
It is generally easier to get started building a monolithic app. We can begin to write code that creates user value without too much thought.
Working in the monolithic codebase is also generally simpler. The entire codebase can be indexed by an IDE providing useful intellisense, there is direct visibility into every part of the system, and since everything is in a single codebase, coordinating changes can be performed in a single commit.
Administration of a single app is also radically simplified. There is much less to monitor or manage.
Performance (+2)
As implied by the fallacies of distributed computing, one unexpected consequence of distributed architectures is some performance penalty incurred through network latency and bandwidth. In memory calls are, thus, faster than network calls. That said, the potential benefits are limited by the available hardware to a given application (even when writing multi-threaded, high-performance code). Resources are shared and are difficult to scale out (as we can with other distributed patterns).
Cost (+1)
A related consequence of axis of simplicity induced by this constraint is a corresponding reduction in cost. Up-front design efforts are reduced as are infrastructure requirements.
Deployability (+1)
Deployment of a monolithic binary can be as simple as copying a directory to a server or using a deploy feature in development tooling (although friends don’t let friends right-click deploy). The improvement of this capability is modest at best. We certainly can’t deploy with the same velocity of more granular architectures given the size of the deployment (the entire application, even for a small change) and the start-up time for an application degrades proportionately with the size of the code base.
Testability (+0.5)
Compared with the null style, testability can be slightly improved - but only slightly. There are few–if any–external dependencies to be aware of, in theory the entire codebase can be tested with minimal coordination cost.
Agility (-1)
A monolithic build artifact requires that any change require a redeployment of the entire system. Testing scope is higher and coordinating releases more difficult.
Scalability (-2)
This constraint introduces scalability challenges. The only available avenues towards scale revolve around either scaling up the hardware the application is running on or scaling out. The latter is severely constrained by the fact that the entire application must be replicated, not merely the handful of components responsible for the lion’s share of the load.
Abstraction (-2)
One key trade-off of the single, monolithic, codebase is that generally abstraction becomes a secondary concern (if at all). Without care, the code becomes tightly coupled with a high degree of connascence. Other constraints will balance this somewhat, but in the context of just this constraint, abstraction is degraded.
Elasticity (-3)
In the same way this constraint degrades scalability, elasticity is even more affected. Quickly responding to bursts in load become challenging as the entire application must be replicated, and the coarse granularity of the application will degrade startup times.
Fault-tolerance (-3)
Since the entire system resides in a single binary, fault-tolerance is adversely affected. Generally the system as a whole is healthy, or it is not. In more fine-grained architectures it’s possible for components to fail without bringing down the entire system.
Constraint: Independent Deployability
This constraint states that the system as a whole need not be delpoyed at one time. Any individual component must be deployable in isolation. This consrtaint cannot co-exist with the monolithic deployment granularity constraint.
Agility (+1.5)
Independent deployability requires some rules around modularity. Clean and stable module boundaries must, therefore, exist (be it in the form of plug-in architecture, event processors connect by async processing channels, independant services, or service layers). These module boundaries in place, combined with independent build and deployment pipelines, significantly improve overall agility. To respond to change, a module can be create or modified and deployed with low overall risk to the rest of the system. Change scope remains constrained and deployment risk reduced increasing overall delivery velocity.
Deployability (+1)
In the same vein of Agility, overall deployability is improved.
Elasticity (+1)
Independent deployability improves component independence and improves elasticity.
Evolvability (+1)
The independant deployability constraint enables different parts of the system to evolve at different rates. Adding or changing functionality is often as simple as a single, scoped, focused deployment.
Scalability (+1)
Independent deployability improves component independence and improves scalability.
Cost (+0.5)
The capability of surgically-precise deployments reduces the overall total cost of ownership of the system. This capability is limited, however, as independant deployability typically requires additional investment in build and deployment infrastructure which incurs a cost penalty. In aggregate, the trade-offs of this constraint are a small net positive.
Simplicity (+0.5)
Although development and management of independant build and deployment pipelines introduce complexity and require some specialized skills, once this infrastructure is in place, the system as a whole is generally easier to maintain and modify. Again, in aggregate, the trade-offs evaluate to a modest net positive.
Constraint: Shared Database
This constraint states that the entire application utilizes a common database. While this is often a default of some abstract styles and patterns, it still strengthens and weakens capabilities and should be explicitly noted.
Cost (+1.5)
Generally sharing a single, shared database reduces licensing costs, hosting costs, and reduces development costs. Generally this also reduces data storage redundancy as there is much less need to replicate data to be visible to other application components.
Simplicity (+1)
Administration is simplified by virtue of having a single database to manage. Design is also simplified as all data modeling can be done at the application level rather than domain level.
Deployability (+0.5)
Deployment is generally straightforward as changes to a single database have reduced coordination costs. The improvement is modest, however, as DB changes at this scale can affect availability and introduce risk if schema that other components rely on change.
Configability (-0.5)
Configurability is reduced as any changes must be applied system-wide. A one-size-fits-all approach is generally required under this constraint.
Fault-tolerance (-0.5)
A single database becomes a single point-of-failure. Although most database management systems bring high-availability configuration options, if one database (the only database) is unavailable, the entire system is unavailable.
Scalability (-0.5)
Databases are notoriously difficult to scale. Multiple databases responsible for different parts of the data provide some level of parallelism and increase total capacity, a single database may be limited to scaling up.
Agility (-1)
Database changes potentially require coordinating with all teams and must be regression tested across all components. It can be very difficult to tell which teams are using various tables. Consequently, any change introduces risk which reduces change velocity.
Evolvability (-1)
The high coordination cost and testing scope also degrades evolvability.
Elasticity (-2.5)
As a single, shared resource, the system as a whole becomes less elastic because there is a ceiling to the single database’s capacity.
Constraint: Separation of Concerns
This constraint further narrows the technical partitioning constraint by being more prescriptive around how layer boundaries and modularity are defined. This constraint defines that code is not simply defined by technical area, but also logical concern.
Cost (+2)
Development and maintenance costs are reduced by adding this level of modularity to code. Developers may develop deep domain expertise in business logic (or subset of the business logic) which further reduces cost.
Testability (+1)
This constraint further reduces testing scope for any given change.
Agility (+1)
Agility is improved as the code generally has better boundaries, reduced testing scope, and potentially change scope.
Simplicity (+1)
This constraint generally improves simplicity of development and maintenance of the code. It is well-defined way to develop software, and this constraint improves understandability of the system components as well.
Evolvability (+0.5)
Evolvability is slightly improved as a consequence of the factors detailed above.
Constraint: Plug-In Architecture
This constraint prescribes opinionated module boundaries and module behavior. A module conforms to this constraint if if implements an interface defined by a core system, supports a standardized grammer, and only interacts with the core system through published, stable APIs. This constraint requires a uniform-interface constraint. Further, modules must be discoverable, installable, swappable, and removable at runtime. Many capabilities are impacted by this constraint.
Configurability (+4)
This constraint provides the system with a high degree of configurability. At a high level, the functions of the system are defined by composition of user-selected plugins. Plugins typically offer their own configuratibility options as well.
Fault-tolerance (+3)
This constraint introduces natural bulkheads in the system. An unhealthy or otherwise malfunctioning plugin can quickly be identified by the core system and isolated or disabled. Fault tolerance can be improved on diminished based on other architecture constraints.
Abstraction (+2)
The nature of prescribed module boundaries, grammars, and APIs provide a stable abstraction between the core system and plugins. This abstraction generally makes for safer changes because the nature of this constraint makes it difficult for changes to bleed into the public interface of any given plugin.
Workflow (+2)
A workflow capability may be introduced through combination and orchestration of plugins. Care must be taken to maintain fault-tolerance as well as runtime dependency management.
Agility (+1.5)
Agility is improved as the module boundaries, prescribed grammars, and core-system APIs are stable and well defined. Enhancements to a plugin generally do not bleed through to the boundaries, constraining changes within the black-box of the plugin. Likewise delivering new functionality is typically as simple as developing a new, relatively small, plugin. This constraint, therefore, enables developers (and, by extension, business) to respond to change quicker. The core system and plugins may independently evolve.
Evolvability (+1.5)
With this constraint, changes to the system are as simple as creating a new plugin or modifying and existing one. The composable nature of plugins also results is a system that can continually be extended in unexpected ways after deployment.
Integration (+1.5)
This constraint prescribes interfaces, grammars, and API interaction. As long as these are stable, the overall capability of integration is improved.
Interoperability (+1.5)
Interoperability is similarly improved alongside integration due to the prescriptive and opinionated interfaces.
Cost (+1)
Total cost of ownership is improved by this constraint. Cost of change is generally constrained and new capabilities can originate from the core-system maintainer, 3rd party developers, or the open-source community.
Performance (+1)
This constraint suggests code modules that locally extend the core system. When contrasted with calls to external modules over the network, executing code within a plugin doesn't require TCP overhead, network latency, or suffer from bandwidth issues. The improvement is modest, as performance is constrained by the hardware running the core system and plugin.
Testability (+1)
This constraint is very prescriptive on module boundaries and constrains interactions. Functional testing scope becomes better defined as a consequence and integration testing scope is fairly constrained.
Deployability (+0.5)
Deployability is improved as plugins follow a clear deployment process that is generally low-risk. A component registry may add up-front complexity to this constraint.
Simplicity (-1.5)
The necessary development of module grammars and stable APIs is non-trivial. Likewise the infrastructure for managing plugins at runtime also introduces some complexity.
Constraint: Uniform Interface
This constraint prescribes a stable, defined, uniform interface between components. This may manifest in many ways. A mature implementation of the REST architectural style generally follows the conventions of the web (URIs as identifiers, HTTP request methods for retrieving or modifying resource state, and a standardized set of response codes). In a plugin architecture, it may be a set interfaces, standardized grammer, limited interaction via stable APIs, and well-defined exceptions. Applying this constraint to an architectural style modifies capabilities as follows.
Abstraction (+3)
Interfaces, APIs, and grammars abstract implementation logic from integration logic significantly improving the abstraction of components in the system.
Cost (+2)
With this constraint, and its related abstraction, change scope is reduced, integration cost is reduced, deployment cost is reduced.
Integration (+1.5)
This constraint prescribes a comprehensive standardized interface for interaction. As long as this are stable, the overall capability of integration is improved.
Interoperability (+1.5)
Interoperability is similarly improved alongside integration due to abstraction and the prescriptive and opinionated interfaces.
Agility (+1)
In the same manner that this constraint improves TCO (including long-term development and maintenance costs), change cost and risk are reduced which improves release velocity. This capability is tempered somewhat by the overhead of writing code to interact with a uniform interface (and the development and maintenance of the interface in the first place). Also, once these interfaces are defined they become difficult to change, reducing some of the agility advantage of this constraint.
Evolvability (+1)
Implementations are decoupled from the functions they expose, which encourages independent evolvability.
Simplicity (+1)
By applying the software engineering principle of generality to the component interface, the overall system architecture is simplified.
Fault-tolerance (+0.5)
A uniform interface not only constrains how components interact happy path, but also how error states are communicated. Visibility of success and failure, health and malfunction are thus clearer across component boundaries and the system may adapt as necessary without intimate knowledge of component internals.
Testability (+0.5)
Testability is modestly improved due to the limited integration test scope and due to the abstraction this constraint provides.
Summary

This pattern brings a high degree of modularity, evolvability, configurability, adaptability, and agility while retaining most of the low cost and simplicity of other monolithic architectures. Although mostly seen in desktop apps and self-hosted software, many of the constraints have very broad applicability across many potential problem domains. It is certainly an abstract style worth keeping in your toolbox for projects where this pattern can put a project on the road to a Tailor-Made Fit.