Third-Way Web Development Part I - History

When I look back on my career in technology, I’ve been seduced, over and over again, by this idea that best practices exist and that I can consider my work “good” so long as I follow those best practices. In some ways it would be wonderful to work in a field where there are absolute “right” and “wrong” answers but I no longer believe software engineering is one of those fields. Every single decision we make has consequences and whether these consequences are positive, negative, or mixed will depend on the context. It’s all just a set of trade-offs, and the key to making good decisions lies in understanding what matters most and evaluating the trade-offs in this context.
There are no best practices, only trade-offs.
-First law of Software Architecture
We’ve somehow gotten into this weird place in web development where the consensus seems to be that an absolute set of best practices exist; where the only meaningful decisions surround which framework to use and how to find the optimal implementation details within that chosen framework. Unfortunately the web development space has become so myopically focused on frameworks, tooling, and Single-Page Applications (SPAs) as the de-facto “best practices” that the trade-offs of these approaches are rarely discussed–or even well-understood up front–and, in many cases, the result is an ocean of bloat and accidental complexity that often could have been avoided entirely.
It’s not that these client-side frameworks are necessarily “bad” in fact they certainly offer a great deal of value in the right place. Rather we need to continue to approach software development more mindfully, deliberately, and contextually. This remains a uniquely human skill that current AI models remain a long way off from materially competing with.
My focus, for this series, is not to tell you how to build your next web app, or suggest you need to rewrite your existing one(s); instead I want to begin a conversation about web development framed in a broader context. I want to explore the trade-offs of framework-centric web development that are typically overlooked and introduce (or re-introduce) some ideas that might not yet be on your radar that may offer meaningful alternatives.
A Brief History of the Web and Web Development
Choosing the framework-centric web-development path is a significant and consequential decision; while there are many benefits to this approach–much can be gained–these benefits inevitably come at a cost. Is the cost justified? Sometimes. It depends.
The nature of trade-offs is that we are necessarily giving things up in exchange for what we gain. I can’t really speak to what we’ve lost without first talking about what we once had and how we got to where we are today.
It Started With Information
 (Vannevar Bush)
(Vannevar Bush)
Vannevar Bush was an engineer and inventor most active in the first half of the 1900s. In 1940, then President Franklin Roosevelt ordered the creation of the National Defense Research Council and named Bush as it’s chairperson. The agency’s stated goal was “to coordinate, supervise, and conduct scientific research on the problems underlying the development, production, and use of mechanisms and devices of warfare.” The 1940s was a period of explosive (no pun intended) growth of scientific information and Bush began to speculate that we had outgrown the existing mechanisms to catalog and organize this information.
“…we can enormously extend the record; yet even in its present bulk we can hardly consult it… There may be millions of fine thoughts, and the account of the experience on which they are based… if the scholar can get at only one a week by diligent search, [their] syntheses are not likely to keep up with the current scene.”
-Vannevar Bush
Bush began to daydream about a radical new way to not only organize information, but connect and cross-link it. This culminated in his visionary 1945 Essay As We May Think where he described a hypothetical machine that could both store and link documents and enable nonlinear navigation of these documents. This essay planted the ideas for what Ted Nelson would later dub “hypertext” less than two decades later.
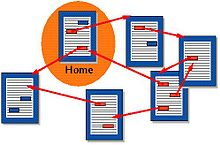
Hypertext was a revolutionary idea that spread among forward-thinking communities in the coming decades and inspired a young computer scientist named Tim Berners-Lee to build ENQUIRE at CERN in 1980, a hypertext system similar to today’s Wikis.
The Birth of the Web
By 1989, Tim Berners-Lee proposed a global hypertext system that would eventually be known as the World-Wide Web. In 1990, he began constructing the key components of a hypermedia system: A hypermedia (in this case, HTML), a network protocol (HTTP, the hypertext transfer protocol), a server presenting a hypermedia API which responds with hypermedia responses, and a client that can interpret the hypermedia (the first web browser). In August, 1991, the very first web page was published (notably, it’s still out there… and it still works).
The web operated on a handful of key concepts. An information resource (e.g. a document, an image, a midi file, etc.), a URL (originally describing the location of the resource, but as the web made physical location increasingly irrelevant, the URL frequently acts as a mere identifier of the resource), HyperText Markup Language which would allow an author to describe the document in a standard way such that a html client to render the document for humans to view and interact with, while pulling in any additional embedded resources (e.g. images) and offered the first hypermedia control; the anchor tag. The anchor tag had an href property enabling the linking of one resource to another; it’s what made the web “hyper.” These URLs, these links could be referenced, saved/bookmarked, embedded, and shared.
During these formative years, resources on the web were largely static but there were plenty of classes of resources that would need to change independently of publishing cycles; dynamic resources. A notable early example of this phenomenon was a Coke Machine at Carnegie-Mellon University which hosted its own web page allowing students to see if their beverage of choice was in stock (and ice-cold) without first having to walk across the campus. That same year, a draft of the Common Gateway Interface was created to standardize how command-line applications (such as the Perl interpreter or c programs) could be integrated with a web server. The need for input to these applications–not just output–led the specification of HTML 2.0 which included a second hypermedia control, the <form> element along with a set of <input> controls. The web was now truly interactive (at least, in a rudimentary sense). Clicking a link would load a new page in the browser window, and submitting a form would serialize the contents of the input tags, send those to the server, which would ultimately respond with a new html document to load in the browser window. Both interactions would completely replace the current contents of the browser window with a new web resource.
A New Type of Application?
Most network applications of this era followed a relatively simple client/server architecture. The application, along with all it’s constituent business logic, rules, and instructions were compiled into a single “fat” client, installed locally on a PC while state existed in a shared database accessible over the network. This fat-client style application could offer a rich and responsive user experience, taking advantage of an available graphical user interface, dynamically updating only the parts of the user interface that truly needed to change; this approach had a significant drawback in how the application was distributed and updated. In effect, this application needed to be manually installed (or upgraded) on every machine on which it ran. Often a complex process of mastering, disk duplication, and distribution was involved; “ship it” literally meant shipping it. The core ideas of agile, embracing change and rapidly responding to it, weren’t just a fantasy; they were utterly impractical. With the advent of HyperCard several years earlier, we saw the potential of hypermedia applications. The web offered a tantalizing possibility of a new type of thin client, especially by 1995, when client-side scripting first appeared in Netscape Navigator.
At this point, the architecture of the web truly took shape. Roy Fielding, one of the early architects of the web, would later dub the architecture of the web “The REST Architectural Style” defined by six constraints:
- The Client/Server Constraint
- The Stateless Constraint
- The Cache Constraint
- The Uniform Interface Constraint
- The Layered-System Constraint
- The (optional) Code-on-Demand Constraint
Hypermedia is central to the Uniform Interface Constraint, where a server provides a hypermedia representation of a resource’s state along with a set of affordances in the form of hypermedia controls to allow a user to interact with that resource.
The architecture of the web offered unprecedented flexibility and evolvability which enabled experimentation with different ways to build applications on the web. Since hypermedia offered a stable abstraction, many server-side scripting languages and server-runtimes were introduced which were immediately available to all existing web clients. While this opened the door to many new possibilities, the fact that every hypermedia interaction required a post-back and full-page refresh left much to be desired in the overall user experience (particularly on a dial-up connection).
Attempts continued to build rich, client-side user experiences within web applications. One of the early attempts to overcome the limitation of a pull page reload on every request was framesets, first introduced inside Netscape 2.0 and lobbied to standardize this feature in HTML 3.0. In effect, framesets enabled a single browser window to be divided (and, potentially further subdivided) into multiple independent pages which could be targeted and refreshed individually. They weren’t popular and were subsequently removed in HTML 5 (although iFrames remain).
Another approach was to extend html to allow embedding of applications into a web page. Java Applets, ActiveX controls, Flash, Silverlight, and numerous others have come and gone. These approaches used the web as a delivery mechanism, but these apps weren’t native to the web and introduced performance, runtime, and security challenges.
Enter Web 2.0
By the late 1990s, Microsoft held a monopoly in the web browser space and they introduced the XMLHttpRequest object to allow their Outlook web client to perform some basic background tasks. It allowed them to moderately improve the UX of their webmail client and strengthen their monopoly. Outlook was widely used and this feature offered web users a superior user experience… but only in Internet Explorer. The other browser vendors followed suit, opening the door for the next revolution. Ajax and Web 2.0.
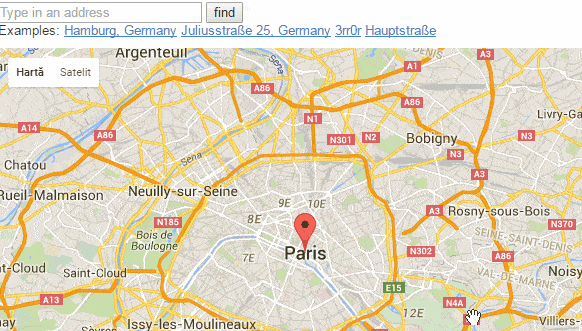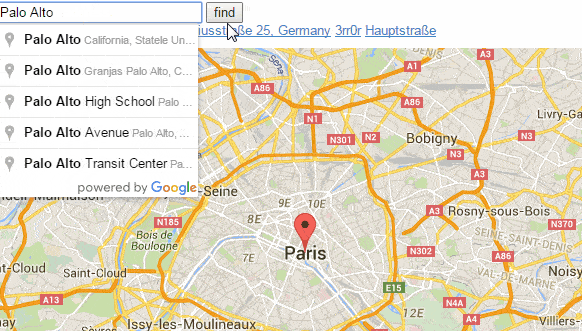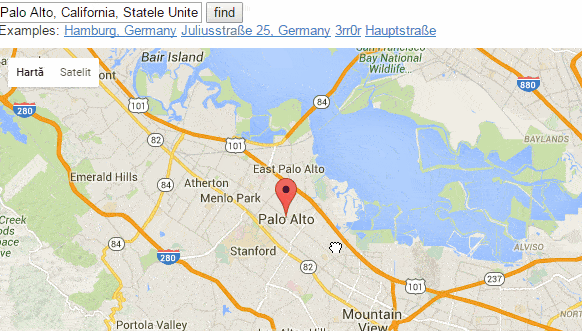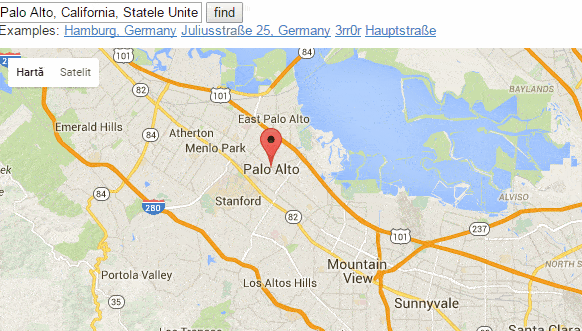 (Google Maps dynamic UI in action)
(Google Maps dynamic UI in action)
Gmail and Google Maps were among the first web apps to show us the user experience we had been dreaming of for over a decade. Beyond mere background synchronization tasks, these apps were taking responses and rewriting parts of the page on the fly. It was a glorious hack, and not in the pejorative sense; like CMU’s internet Coke machine, or the first webcam created to remotely check if there was any coffee in the Trojan Room coffee pot it was brilliant. The bar was raised and there was no going back.
 (the very first webcam)
(the very first webcam)
In the early days, working with XMLHttp objects and using browser native DOM manipulation APIs was not for the faint of heart. These APIs were not yet standardized, and the code quite verbose. A number of new JavaScript libraries popped up providing a browser agnostic API to simplify ajax requests, DOM tree traversal and manipulation, event handling, animations, etc. A new breed of web applications were built using YUI, ext.js, or jQuery (to name but a few). This new paradigm was powerful, but began to erode the foundational ideas of hypermedia.
Declining Hypermedia and a New Ephemerality
By the late 00s, this became an increasingly common sight:
...
<a href="#" id="LoadUserPopup">label</a>
...
The anchor above is no longer a hypermedia control, just a user interface element. HTML was beginning a steady slide from hypertext markup language to mere user-interface markup language. Perhaps this was fine, after all the goal was to run and distribute interactive applications over the web. Did we really need hypermedia at this point or was HTML (as UIML) enough?
As user interfaces became increasingly sophisticated, more and more work was being done inside the browser, dynamically generating and manipulating fragments of markup. The interactivity model was moving to the JavaScript libraries with an increasingly short half-life. While the flexibility and evolvability of the core architecture of the web and its supporting standards enabled this evolution, we arguably began to throw the baby out with the bathwater, coupling to very unstable and leaky abstractions.
While the new ajax-powered era of web development promised applications that would feel modern, any projects that “backed the wrong horse” quickly felt positively antiquated. jQuery emerged as the dominant js library of this era. Apps built with YUI, ext.js, or the myriad others that weren’t rewritten for jQuery quickly showed their age and became harder to maintain due to abandoned plugins and declining developer interest.
Also, as powerful as this approach was, the code was still very verbose, lacked structure, was difficult to test, difficult to debug, difficult to organize. We began to reach the limits of even the library-powered ajax approach.
By 2009, client-side html templating started to emerge with libraries like mustache and handlebars but these applications needed better structure and separation of concerns. In under a year, the MVC, MVVM, and observer patterns began to find their way to the client with AngularJS, Backbone.js, and Knockout being among the leading contenders.
The next hypertext domino to fall was the URL. In the quest to eliminate page refreshes at all costs, these new frameworks enabled the entire application to be downloaded into the browser at once and all internal application navigation was handled by custom, client-side code. We broke the back button and had to figure out how to reinvent it. Navigating directly to a “deep link” often resulted in incorrect application states. Again, we added more complexity to bring this basic behavior back. Increasingly navigating to an app would serve almost no html beyond what is necessary to bootstrap the application. We added more complexity in the form of prerendering and server-side rendering, again, to reinvent what we used to get for free.
By it’s very nature, the web was a natively distributed system. A web page was often a composite of many resources which could be sourced from all over the web. These new client-side applications became large, unwieldly monoliths. It would take many years before the microfrontend pattern would emerge to restore yet another feature of the web we had lost.
Opting In to Tech Debt
Applications built in the early ajax era began to suffer to shifting fashions. I personally saw one application rewritten four times in six years (ext.js -> jQuery -> knockout -> angularJS) and worked with many applications that ultimately ended up using most (or all) of these simultaneously as trends would typically shift mid-rewrite. Of course, at this point, not only did the application need to be changed but so, too, did the entire toolchain. Gulp, Grunt, Webpack, SASS, LESS, Babel, Bazel… The list goes on an on. New framework versions often introduced some number of breaking changes, and an increasing amount of most organization’s development budget shifted from new features and innovation to simply keeping up with trends and applying the latest toolchain and runtime additions to fix what always existed until the latest framework “innovation.” Sections of the app dependent on an old version of a library or framework; or built using an abandoned toolchain or library we relegated to a growing mountain of tech debt.
It soon became clear that coupling to any framework and toolchain was simply opting in to tech debt. If not today, than inevitably soon. Of course, the promise of stability was on the horizon.
The consensus in the early 2010s was that the “smart-money” was on a framework that had the backing of the behemoth that is Google. AngularJS got a lot of attention and many web applications were irrevocably coupled to their particular brand of MVC/MVVM. In 2014, however, we learned that AngularJS was already on the sunset track and brand new and completely different framework, confusingly called “Angular” was the future. Oh, and drumroll… there’s no upgrade path. Admittedly that was walked back slightly following the backlash, but there’s no avoiding it… another rewrite was necessary.
To be fair, the world changed on us very quickly, giving us little time to adapt or figure out the best way to proceed. The web dev space contains some of the brightest minds in the industry and many brilliant ideas have emerged during even the most turbulent framework years.
Today we have largely coalesced around React, Angular, and Vue with the best ideas of each (and the past) cross-pollinating to create a powerful set of tools to choose from. Although nobody is hopping from framework to framework quite like they did 15 years ago, these frameworks continue to regularly introduce breaking changes and every single one of them is a ticking time-bomb of tech-debt.
The Web Remains
This timeline, as I have framed it, might be offensive or, at a minimum, seem unfriendly to web framework apologists (assuming they haven’t stopped reading long ago). I write this not because I hate js frameworks (I don’t, they are extremely valuable, important, and certainly have their place). I write this because we have been frogs in the ever-heating water for so long; so preoccupied with keeping our skills current and our code up-to-date and secure that rarely do we have time for such retrospectives.
Ultimately, we cannot deny the fact that there is no turning back from where we are. If you are building almost anything for the web today, there exists a minimum user experience expectation that can’t be escaped. We get this out of the box with any of the major frameworks. This approach has become regarded as the de-facto “best practice” and apparently the only game in town.
It was a long and hard road to get where we are today. As bright and passionate developers over the past 20 years strove to deliver this dynamic UX and transform the web into a viable application platform, the history has been marked by reacting (again, no pun intended).
Google Maps changed the game, and we reacted with ajax libraries that grew into frameworks. Despite what these libraries gave us, manually manipulating the DOM quickly grew unwieldly. We reacted with client-side templating frameworks and reacted again with MVC/MVVM frameworks to tackle the growing complexity of the explosion of client-side code. New client-side paradigms eclipsed the MVC/MVVM patterns and we reacted. The number of lines of code necessary just to build a “hello world” example has ballooned into the millions. Running $tokei node_modules on a brand new create-react-app in January, 2024 shows an astonishing 3,576,754 lines of code. Bundles were getting out of control so we reacted. New build tools, new compiler optimization techniques… even more complexity.
Operating in a reactive space rarely gives time for forethought or planning. There were many unintended consequences (routing, deep linking, state management, server-side rendering, SEO, accessibility, code bloat, dependency management…) along the way that, again, we had to react to.
We are where we are in web development today because the previous generation of tools weren’t cutting it. Yet, as powerful and useful as these frameworks have proven to be, perhaps they are overkill in many cases.
But what’s the alternative? Many would argue the options are either modern frameworks or going back to those vanilla Web 1.0 days of full page refreshes on every action. I guess it works ok for my minimalist, static html, anachronistic blog but it’s certainly not an option for the SaaS CRM I run.
Fortunately, there exists a third way, a “middle path” if you will. A return to power and simplicity of hypermedia systems but designed to meet 21st century UX expectations.
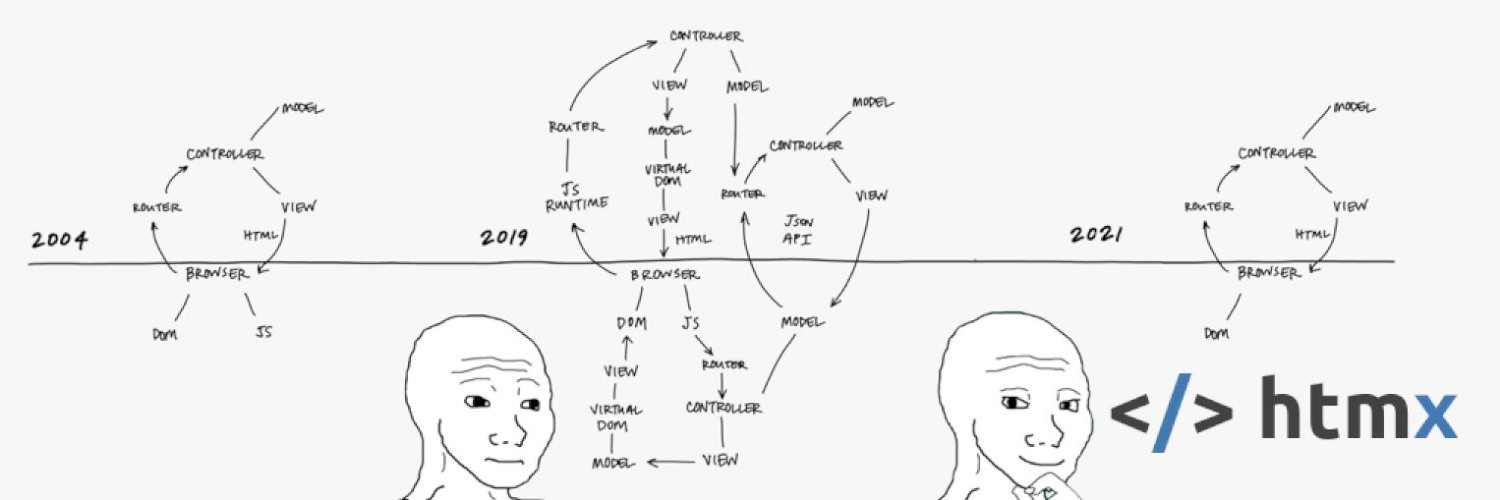
HTMX - The “Third Way”
The third way I present is HTMX, “the newest old way to make web apps.” While mainstream js frameworks have taken the approach of building complex application runtimes that run in a browser, reducing HTML from hypertext markup language to mere user-interface markup language, HTMX takes a refreshingly different hypermedia-first approach by extending HTML to align with the UX demands of modern web apps while avoiding the bloat, complexity, and ephemerality in the process.
My all-time favorite nerdcore rapper, stdout, wrote a fabulous track called “hell.js” that covers first the ecstasy then the agony of modern js frameworks and their complexity ending with the somber line “don’t tell anybody but man I miss jQuery… man I miss jQuery.”
The cynic might be amused that the antidote to “hell.js” that I’m promoting here is… a JavaScript library; but the approach the authors took is materially different and more true to the ideas and architecture of the web than anything I’ve seen before. How is it different? Recall that Roy Fielding defined the REST architectural style–the architecture of the web–by six constraints. The sixth is the optional “Code on Demand” constraint.
“…a client component has access to a set of resources, but not the know-how on how to process them. It sends a request to a remote server for the code representing that know-how, receives that code, and executes it locally. The advantages of code-on-demand include the ability to add features to a deployed client, which provides for improved extensibility and configurability, and better user-perceived performance and efficiency when the code can adapt its actions to the client’s environment and interact with the user locally rather than through remote interactions”
Dr. Roy Fielding - Architectural Styles and the Design of Network-Based Architectures
Long ago we learned that the hypermedia HTML, as currently specified, is insufficient for our modern application needs. In this case, the client requests the code (a 14kb gzipped lib with zero dependencies) that can extend the client’s capabilities (and improve user-perceived performance and efficiency). This is how the web was supposed to work! How is this different from react or any of the other mainstream frameworks? Aren’t they, too, just taking advantage of the code-on-demand constraint? Well, yes but in the process they violate the Uniform Interface constraint. Hypermedia is no longer the engine of application state, it’s an implementation detail stripping away everything hypermedia gave us. It’s UIML, not HTML; different in every respect except syntax.
So we’re violating a constraint, so what? Virtually every system ever created described as RESTful violates one or more of these defining constraints. It’s not about passing some arbitrary purity test, it’s about keeping everything the web already gives us while adding only essential complexity to meet the bar of modern application UX.
Consider that each constraint is chosen to elicit certain system qualities (capabilities, -illities, non-functional quality attributes… whatever you want to call them), violating constraints inevitably degrades or eliminates system qualities. This is fine if those -illities aren’t important but, as the timeline presented above shows, they are almost always important. More code had to be added to fix what got broken as a result of violating that constraint, leading to an increasing amount of complexity and hell.js. In other words, Half of the complexity was figuring out how to best create the dynamic UX of the modern web, and the other half was dealing with the accidental complexity our chosen approach introduced. Beyond what more code (and more dependencies, and more tools, and more moving parts) has been able to patch, one key aspect of the web remains broken; it’s evolvability. JS framework code is going to break orders of magnitude more frequently than HTML (or even extended html) due to a lack of stable abstractions.
What about HTMX breaking changes?
I’m glad you asked! It’s not an issue.
HTMX is declarative, not imperative. HTMX is predicated on the core philosophy of “what if HTML natively included a set of features that better aligned with modern UX needs?” Rather than building yet another js library or framework that you code with, the HTMX simply introduces a set of meticulously planned and well-though-out set of extensions to HTML.
You don’t code with or against it directly, you simply write HTML. HTMX adds new properties to html elements that the browser engine knows how to process by virtue of code on demand. The entire library could be easily rewritten (it’s only 3500 lines) without breaking a single client since all it does is finds and processes the tag attributes as declared rather than requiring direct coupling to the implementation of a framework. Also notably, HTMX implements a zero-clause BSD license to all-but-eliminates the risk of a the library becoming abandonware.
I am currently running V1.9.10 extensively in production however 2.0 is on the horizon. Normally a major version release in the webdev world indicates a major breaking change. I have looked through the v1.x-v2.x upgrade guide and even 1.x - 2.x requires zero changes for almost everyone except for plugin developers and a small set of folks who implemented a niche feature on the 0.x version and did not upgrade when v1.0 was released. Basically this nonsense is a thing of the past:
Tune in for part II where we will see HTMX in action in the context of a real-world, production application. I promise you this: it will not be a panacea. Remember, everything is a trade off. There are no best practices, just what’s best in the context of whatever you’re building next.