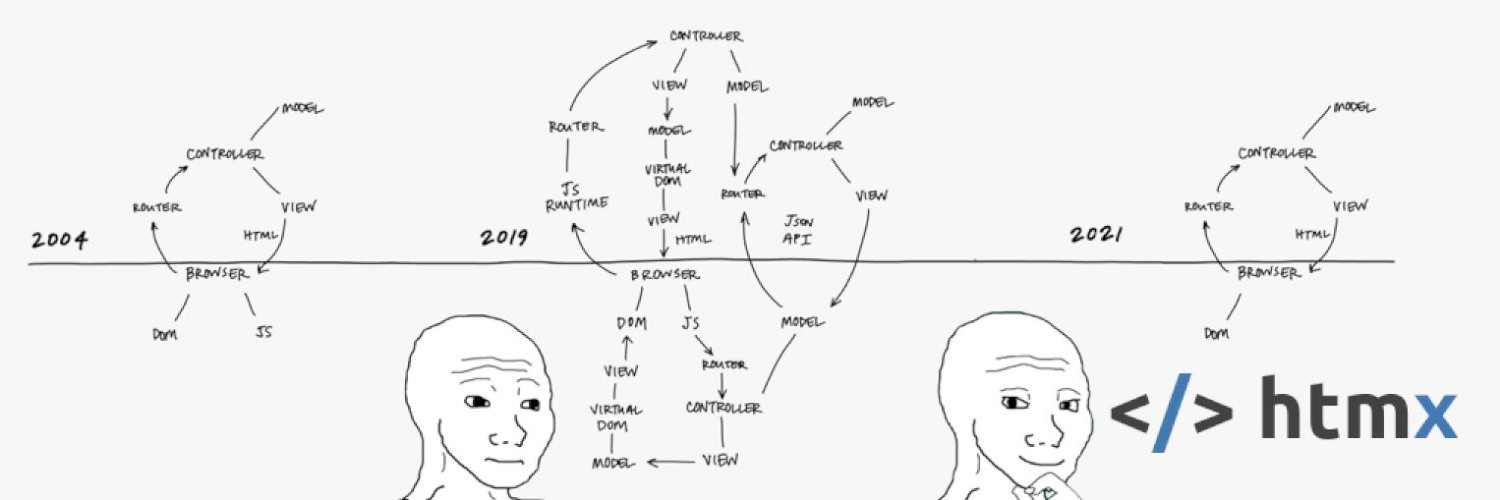
This post picks up from part I which broadly tells the story of where we are currently and how we got here; ultimately introducing HTMX as the “third way.” It serves as the background and context for this post. If you haven’t already read it, go ahead… I’ll wait.
Now that the background is out of the way, let’s look in depth at HTMX. Rather than the usual quickstart or toy examples, we’ll be looking at this in the context of a real production application already in the wild. We’ll modernize a legacy MVC application, examining the UX without and then with HTMX.
When I look back on my career in technology, I’ve been seduced, over and over again, by this idea that best practices exist and that I can consider my work “good” so long as I follow those best practices. In some ways it would be wonderful to work in a field where there are absolute “right” and “wrong” answers but I no longer believe software engineering is one of those fields. Every single decision we make has consequences and whether these consequences are positive, negative, or mixed will depend on the context. It’s all just a set of trade-offs, and the key to making good decisions lies in understanding what matters most and evaluating the trade-offs in this context.
There are no best practices, only trade-offs.
-First law of Software Architecture
We’ve somehow gotten into this weird place in web development where the consensus seems to be that an absolute set of best practices exist; where the only meaningful decisions surround which framework to use and how to find the optimal implementation details within that chosen framework. Unfortunately the web development space has become so myopically focused on frameworks, tooling, and Single-Page Applications (SPAs) as the de-facto “best practices” that the trade-offs of these approaches are rarely discussed–or even well-understood up front–and, in many cases, the result is an ocean of bloat and accidental complexity that often could have been avoided entirely.
REST is the architecture of the web and the web has seen unprecedented growth and evolution since its inception over 30 years ago. A web of static documents gave rise to the read/write web–the so-called web 2.0. New media types and formats have evolved, protocols have become more powerful and more secure. In short, the web has only grown bigger in scale, more powerful in terms of capabilities, and continues to evolve. The human web is a marvel of software engineering and its longevity is a testament to the vision its founders and architects. Unlike much of the software I use today, I have never opened a web browser to a message that the back-end of the web has undergone a breaking change and I would need to download new software before continuing.
At some point in the first decade of the 21st century the web crossed an inflection point; machine-to-machine API calls eclipsed human traffic on the web. Many of these APIs have been labeled REST APIs despite many–perhaps even most–of these APIs fail to exhibit the qualities elicited by truly following the REST architectural style. Consequently, the machine web consists of a lot of brittle integrations that require countless person-hours to craft and maintain. To be clear, I’m not here to get on my soapbox about how all these sinners are “doing REST wrong”; I really don’t care. Not every API needs to–or should–be a REST API. The REST architectural style is a very specific tool to solve specific problems.
“Some architectural styles are often portrayed as “silver bullet” solutions for all forms of software. However, a good designer should select a style that matches the needs of a particular problem being solved.”
-Dr Roy Fielding
Architectural Styles and the Design of Network Based Architectures
Fundamentally I want to talk about some of the overlooked aspects of this architectural style and how they can be implemented to eliminate problems with versioning, evolution, and flexibility. Today we’re focusing on content negotiation.
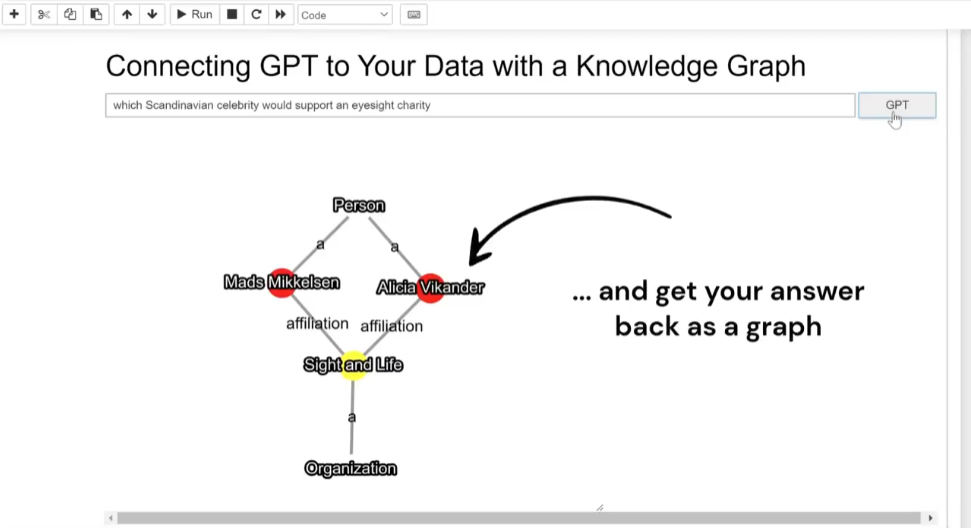
A few weeks ago I wrote an article on how investing in structured, semantic data can help move tools like ChatGPT from the “Trough of disillusionment” to the “plateau of productivity” and create intelligent agents that are actually intelligent. The core was that standardizing on REST Level 1 (or better) and beginning to layer in JSON-LD could provide a more meaningful and factual foundation for generative AI like GPT3 to deliver revolutionary value to organizations.
Less that three weeks later, Tony Seale, a Knowledge graph engineer, posted a brief demo video of these ideas in action.
Since ChatGPT became publicly available last November there has been an explosion of interest, articles, blogs, videos, arguments for-and-against; it can be difficult to separate out the hype from the reality. If you haven’t yet played with the public beta, it’s worth taking a look; first impressions are often downright startling.
One of the most impressive capabilities might be ChatGPT’s ability to seemingly answer questions asked in a casual, conversational manner and many hailed this as “the future of search” with Microsoft and Google both scrambling to integrate these capabilities into their search engines. A mind-bogglingly complex language model trained on a web-sized corpus of text boasts stunning capabilities although it doesn’t take long to discover that beneath ChatGPT’s impressive grasp of language there is a serious lack of knowledge. Google’s parent company, Alphabet, recently lost 8% of its market cap–roughly $100b USD–after their live-stream conference demonstrated Bard, their language model, returning incorrect answers.
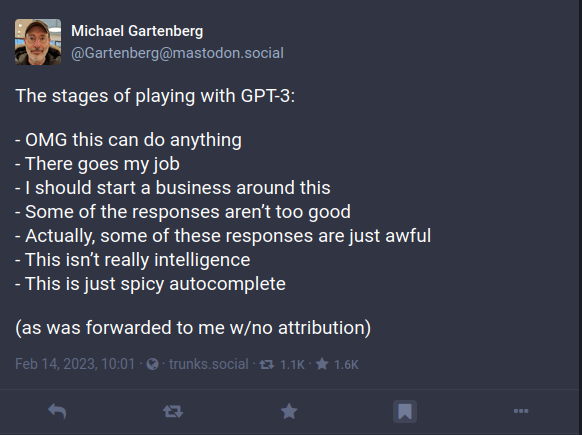
The Mastodon post above summarizes my–and so many other’s–experience. Never in my 20+ years in the industry have I seen a technology move from the “Peak of Inflated Expectations” to the “Trough of Disillusionment” so quickly (see Gartner Hype Cycle). There is something powerful here, especially if it can be integrated with actual knowledge. Forward-thinking organizations are adopting the existing standards and architecture that just might be the key to unlocking the dream that GPT-hype represents. The first step may be as simple as evolving your API strategy.
This is a talk that I have been privileged to see some early drafts of its development. I’ve been eagerly awaiting the finished product. Nimisha Asthagiri joins Scott Davis to lay out the vision of Solid and Pods. It is a delightfully protopian vision, and one that is eminently in reach.
In this talk, Nimisha and Scott explore Tim Berners-Lee’s new vision for the Web – Solid and Pods – where user data is “at the beck and call of the users themselves… a future in which [web] programs work for you”. This is an alternative path where privacy and resiliency are at the heart of our system architectures. A path where the web’s pendulum swings back to decentralization. A path that leads to a fundamentally user-centric tech ecosystem.
This question, it would seem, has been answered countless times on countless blogs, articles, conference talks, papers, etc. yet here I am, joining the throng to tilt at this windmill.
My understanding of REST has been evolving continuously over the past 15+ years. I continue to find new nuances, new applications, new patterns, and rediscover concepts that I once completely misunderstood. I have brilliant friends and mentors, but I’m an autodidact at heart and more often than not, they merely illuminate the path. As I’ve sought to navigate this life and the information space we call the web, I have learned being self-taught is fraught with peril.