What is Rest


This question, it would seem, has been answered countless times on countless blogs, articles, conference talks, papers, etc. yet here I am, joining the throng to tilt at this windmill.
My understanding of REST has been evolving continuously over the past 15+ years. I continue to find new nuances, new applications, new patterns, and rediscover concepts that I once completely misunderstood. I have brilliant friends and mentors, but I’m an autodidact at heart and more often than not, they merely illuminate the path. As I’ve sought to navigate this life and the information space we call the web, I have learned being self-taught is fraught with peril.
The web is full of contradictions. I believe most “educational” content in our industry on the web today falls into three categories:
- Beginners summarizing a concept they’ve just learned
- Experts producing a synthesis of deep ideas they’ve explored
- Biased engineers publishing content to validate their biases
All three have there place. I believe the best way to learn a concept well is to teach it. Beginners also possess a fresh perspective on concepts and topics an expert might take for granted, assuming the audience already understands these deeply. The experts also provide lofty shoulders for the rest of us to stand upon. To quote Donald Knuth
What I do takes long hours of studying and uninterruptible concentration. I try to learn certain areas of computer science exhaustively; then I try to digest that knowledge into a form that is accessible to people who don’t have time for such study.
-Donald Knuth
Even the work of biased engineers has it’s place. Some of the greatest innovations have come from luminaries and thinkers who had the audacity to ask “why must it be this way?”
Each of these three types of content can also be bad. The challenge is they all look mighty similar and it can be hard to discern which is which.
I don’t claim to possess the level of self-knowledge and objectivity necessary to gauge which category this piece (or others on this site) fall into. I only ask that you read, see what resonates and what works, and draw your own conclusions.
What does REST even mean
“When I use a word,” Humpty Dumpty said, in rather a scornful tone, “it means just what I choose it to mean- neither more nor less.”
-Lewis Carrol
REST is, undoubtedly one of the most maligned and misunderstood terms in our industry today. So many different things have been called REST, that the world has virtually lost all meaning. Many systems and applications that self-describe as “RESTful” usually are not, at least according to REST as defined in Dr. Roy T. Fielding’s 2000 Dissertation, “Architectural Styles and the Design of Network-based Software Architectures”.
The wild success of the architecture derived by Dr. Fielding led many to want to emulate it (even when it was inappropriate to do so). As a shorthand, organizations began referring to “RESTful” systems, which exposed “RESTful” APIs. Over time “REST” became a buzzword referring to a vague generalization of HTTP/JSON APIs that typically bear little to no resemblance to the central ideas of REST (and thus elicit few of the benefits). This is, generally, ok; not every application benefits from the constraints and discipline that REST actually prescribes. My only objection is that we continue to call these corruptions of the architectural style “REST” despite Dr. Fielding giving us a handy naming scheme for deriving our own architectural styles.
“REST is not necessarily good. There can be RESTful system which are bad systems; and there are systems that are very, very good systems which have nothing to do with REST.”
-Dylan Beattie The Rest of ReST
Because there is such a wide variety of patterns, styles, and APIs labeled as “REST” Leonard Richardson developed the Richardson Maturity Model in 2008 to classify Web APIs based on their adherence and conformity to the principles of REST.
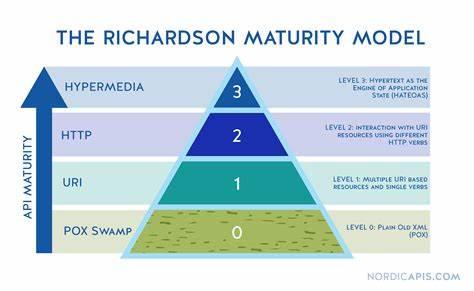
In short, virtually ever developer has seen APIs that have been incorrectly called “RESTful” APIs (typically RMM level 0 or 1) yet only a vanishingly small number of developers have actually truly worked with true RESTful APIs and systems built according to the REST architectural style.
So if we want to move up the maturity model, some key concepts need to be embraced beyond sending and receiving JSON over http.
Resources and Abstraction
The very first network APIs created took the monolithic programming paradigm and distributed parts of the application. In short, developers took a monolithic application, broke it into multiple pieces, but essentially kept the same paradigm. This is called Remote Method Invocation (RMI) or Remote Procedure Call (RPC). Essentially, instead of making the method call using the local stack, we made the method call over the network. There have been various mechanisms since this idea first emerged including CORBA, RMI, DCOM, and even gRPC; but the idea remains the same.
A consequence of this decision is that client and server are often tightly-coupled and highly connascent. It is difficult to evolve the client and server separately, and deploying a change to one component requires deploying additional components simultaneously. Independent evolvability and release cycles are desirable in certain distributed architecture patterns like microservices or where the client implementations are not controlled and must be long-lived.
One of the core ideas of REST is that of the Resource Abstraction. In short, we never expose behavior (functions, methods, etc.) in our APIs. Instead we expose resources.
What is a Resource
A resource is anything that we care about. It could be a document, it could be an image, it could be a paragraph, a person, an pump, an abstract idea, a category, a term, or a concept. In short, everything is a resource.
A resource is something that we care about enough to name and, perhaps, has state we want to observe and possibly mutate. We assign identity to resources in the form of an HTTP URI (or IRI). We use that URI not only as an identity, but it also describes how we retrieve and interact with that resource. We can now globally identify a resource and, if we use http URIs, we have a mechanism to interact with representations of that resource.
Representations
When a client performs a GET request on a resource, we’re given a representation of that resource. A GET on a part URI won’t download a flange or a 2mm machine screw, but it will return a representation of that resource. Typically this will be a JSON-LD document about the part. We will likely create multiple representations of that JSON-LD document as we evolve APIs; clients select representations they care about using content-negotiation.
For another example of representations of a document, let us consider a document. The document itself is a resource with identity (e.g. http://example.com/document/name/employee-handbook). The URI uniquely identifies the resource (the employee handbook). That is the resource. Now, the employee handbook might be available in PDF, docx, rtf, txt, and SVG formats. Those are representations of the employee handbook resource. REST dictates that all of those documents have the same URI (even though they may be different files in the filesystem). We use the same URI because anything said about the word document in our knowledge graph (e.g. author, title, creation date, last-modified date, etc.) is also true of the PDF. To retrieve a PDF or SVG, we perform a GET operation on the URI and use content negotiation to request a representation with mimetype application/pdf or image/svg+xml respectively.
Semantically Constrained Interactions
In the above section on resources we discuss the prohibition of remote method calls and exposing behavior. With this prohibition in place, how do we effect behavior in a RESTful system? We follow the uniform interface constraint of the REST architectural style. We have a universal set of methods to accomplish all things within UV APIs. Those methods are:
- GET (a safe, idempotent, read-only operation)
- POST (a non-safe, non-idempotent, creation operation)
- PUT (a non-safe, idempotent, create-or-update operation on a known URI)
- DELETE (a non-safe, idempotent, delete operation on a resource)
- PATCH (a non-safe, idempotent, partial update operation on a resource)
- HEAD (a safe, idempotent, read-only request for metadata)
- OPTIONS (a safe, idempotent, read-only request for a list of operations permitted on this resources in the context of the current user)
Network Effects
One of the most powerful aspects of the REST architectural style is the potential for network effects. Tim Berners-Lee understood this aspect in his original proposal for the web and we’ve seen its success. As we apply these ideas to move beyond connecting documents and continue connecting data and knowledge, this becomes increasingly powerful.
“Everybody has a ‘REST’ API, everything is a resource. So what? How do we get business value out of all of these endpoints that we’re creating and get out from the hell of building single application capabilities out of everything we’re building? Why can’t we use them a utilities and resources for the business so we can combine them ways that weren’t planned for in the first phase of their life?”
Dr. Peter Rodgers, inventor of microservices
In his 50 minute lecture on “Resource-oriented Microservices”, Dr. Rodgers lays out exactly how REST enables platforms to become exponentially more powerful.
One of the most powerful aspects of REST/Resource-oriented systems is that of compositing. Think about how we use compositing in other forms of engineering like construction. We take two resources, for example Iron and Carbon. When we combine them we get a new composite, steel. Steel has properties that neither iron nor carbon have on their own. When we composite steel and concrete, we get reinforced concrete. Just like steel, the whole is greater than the sum of their parts. In fact, everything we have in today’s modern world is composites of composites of composites of the same 109 or so basic elements.
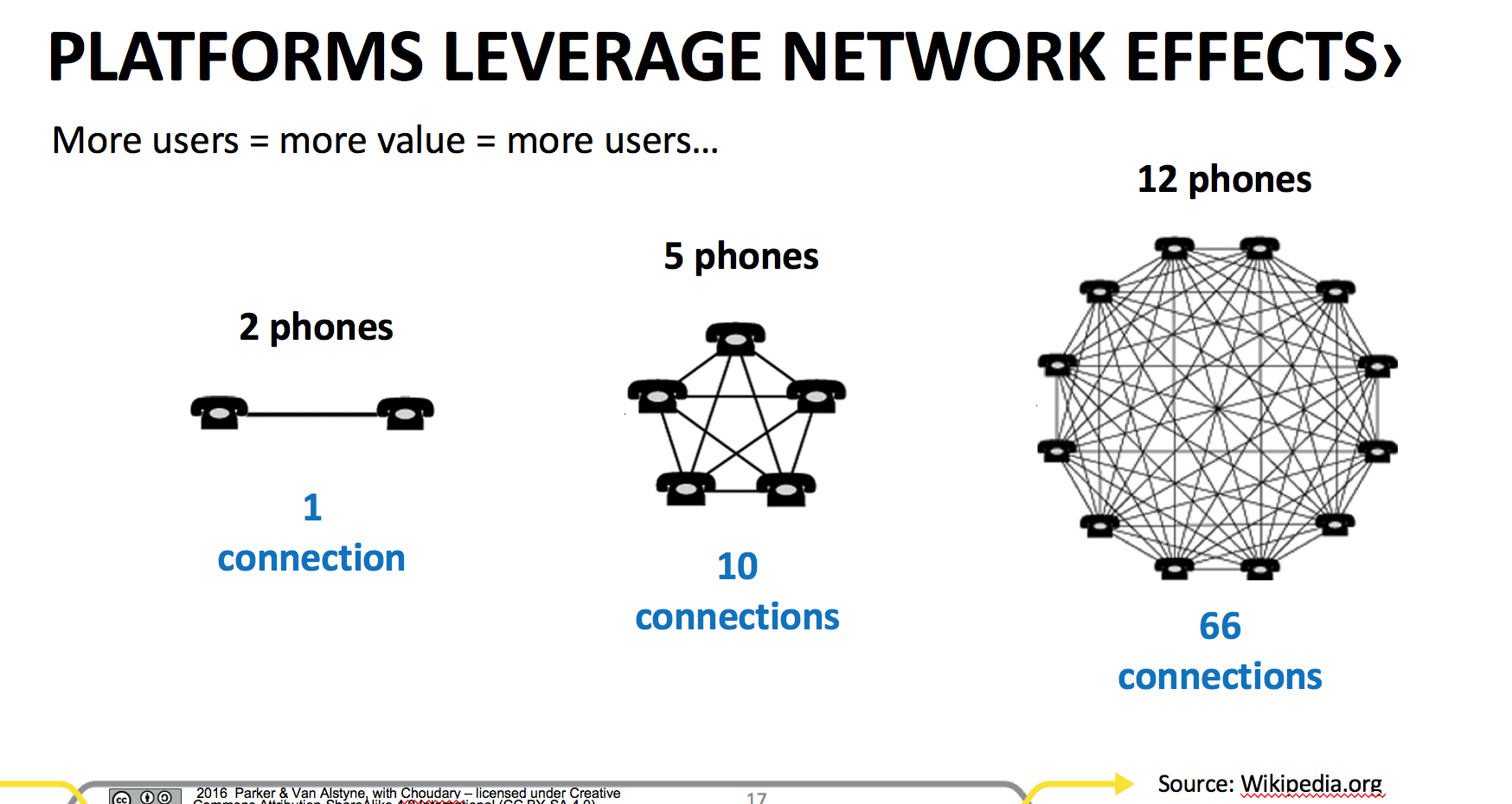
Metcalfe’s Law
The value of the network increases to the square of the number of nodes in the network.