The Future Beyond 'Spicy Autocomplete'

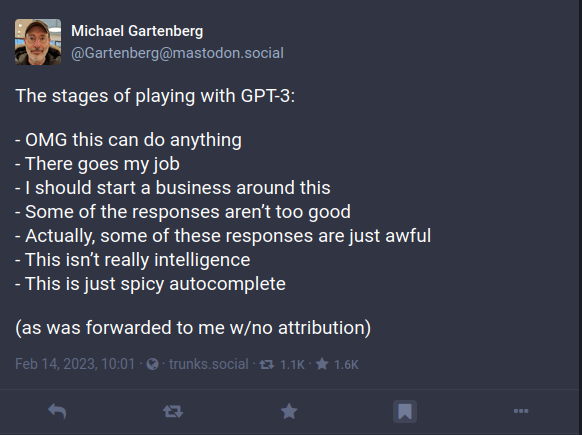
Since ChatGPT became publicly available last November there has been an explosion of interest, articles, blogs, videos, arguments for-and-against; it can be difficult to separate out the hype from the reality. If you haven’t yet played with the public beta, it’s worth taking a look; first impressions are often downright startling.
One of the most impressive capabilities might be ChatGPT’s ability to seemingly answer questions asked in a casual, conversational manner and many hailed this as “the future of search” with Microsoft and Google both scrambling to integrate these capabilities into their search engines. A mind-bogglingly complex language model trained on a web-sized corpus of text boasts stunning capabilities although it doesn’t take long to discover that beneath ChatGPT’s impressive grasp of language there is a serious lack of knowledge. Google’s parent company, Alphabet, recently lost 8% of its market cap–roughly $100b USD–after their live-stream conference demonstrated Bard, their language model, returning incorrect answers.
The Mastodon post above summarizes my–and so many other’s–experience. Never in my 20+ years in the industry have I seen a technology move from the “Peak of Inflated Expectations” to the “Trough of Disillusionment” so quickly (see Gartner Hype Cycle). There is something powerful here, especially if it can be integrated with actual knowledge. Forward-thinking organizations are adopting the existing standards and architecture that just might be the key to unlocking the dream that GPT-hype represents. The first step may be as simple as evolving your API strategy.
Free Organizational Knowledge
Data today is trapped in enterprise applications and web platforms. Until we recognize and take action on the core problem, the situation will continue to deteriorate.
The dominant paradigm in software development today is enterprise information silos. The Semantic Arts calls this “Application Centric” thinking. Our data is presented through custom software that typically provides human context in the form of a UI, and business context/semantics in the form of application code. We’ve become so accustomed to this approach that when we want to do something new with that data (often combined with data in other information silos) we hire developers to read API documentation, interpret implied semantics from human naming conventions, and write even more custom software to perform integration for a new, narrow, use case. Our capacity to build these new one-off solutions increases linearly while the amount of data we produce increases exponentially.
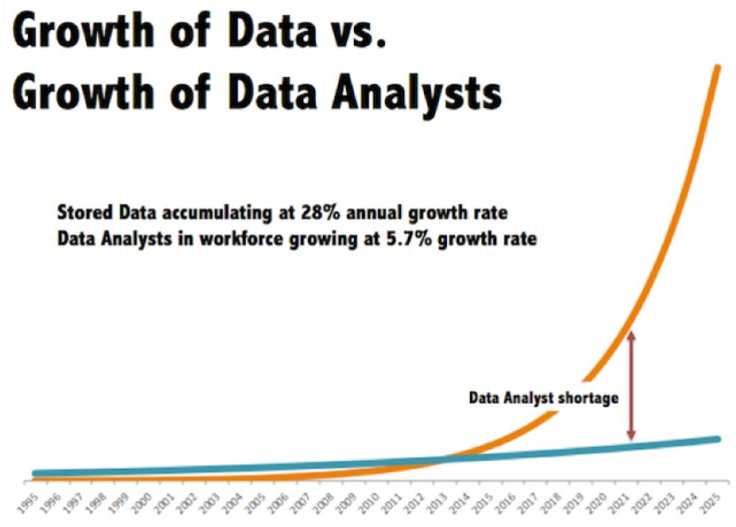
Part of the excitement of ChatGPT is that it can seemingly quickly answer novel general questions, while the application-centric approach favors answering well-defined specific questions (with new capabilities requiring more developer time and considerable latency). Data integration typically consumes 35-65% of an organization’s IT budget.
The problem, at its core, is that we have allowed applications exclusive control over the data they manipulate. At first blush this seems necessary and desirable. The validation, integrity management, security and even the meaning of most of the data is tied up in the application code. So is the ability to consistently traverse the complex connections between the various relational tables that we euphemistically call ‘structured data.’ This arrangement seems to be necessary, but it isn’t. It is not only not necessary, it is the problem.
Decades of ‘best practices’ in implementing application systems, and as much time spent cost-justifying each new application, have led us to believe what we’ve been doing is value added. It is anything but.
Increasingly we’re seeing that ML, alone, is not the answer.
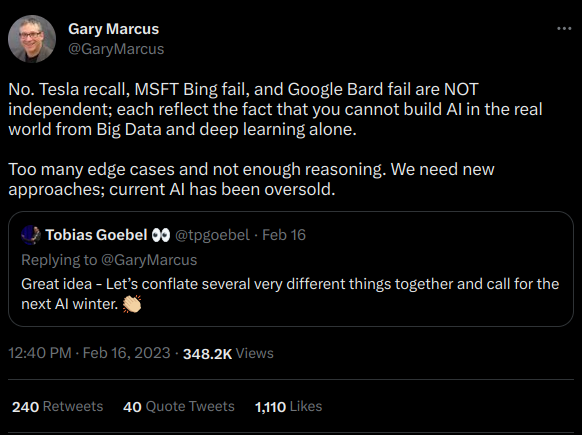
The promise of spending 10s of millions of dollars on compute to train complex models as a “quick fix” to this problem is rapidly fizzling out. As Gary Marcus, author of Rebooting AI, said in the tweet above, more is needed.
Becoming Data-Centric
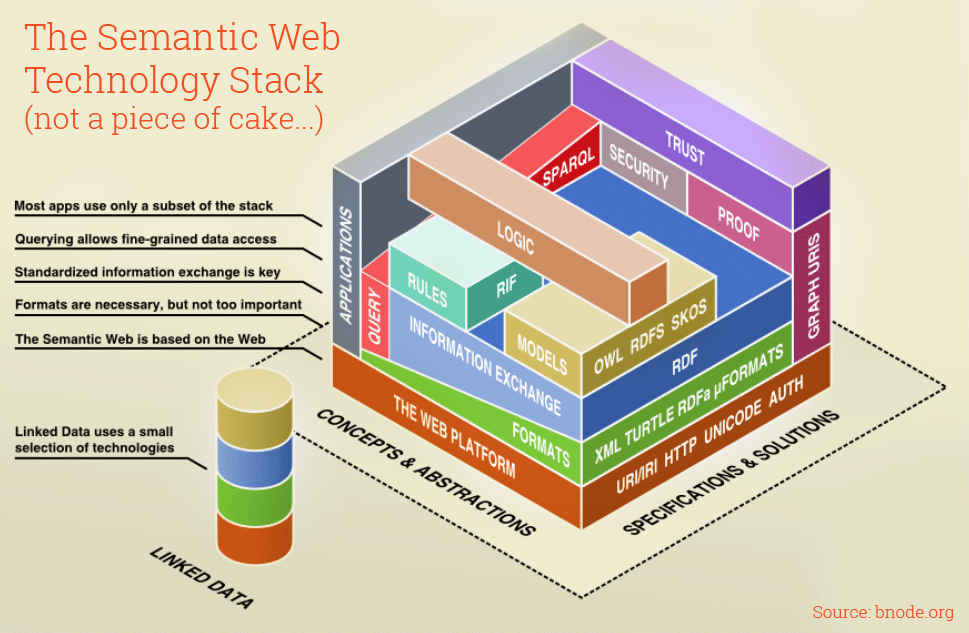
The REST architectural style provides an architectural foundation to free data and its underlying context and semantics from any particular application. Unfortunately, REST is a wildly misunderstood and maligned topic which prompted Leonard Richardson to develop the Richardson Maturity Model to classify so-called “RESTful APIs” based on their adherence to the architectural constraints that define REST. In recent years, popular API approaches (e.g. graphQL or immature “REST” apis) have focused on increasing developer productivity in efforts to glean new insights and integrate new information silos that might be better avoided in the first place.
If your API conforms to Level 1 (stable identifiers for resources), your organization is already well on its way to moving towards the Data-Centric paradigm that can power more holistic views and insights. This is often harder than it may seem, and requires careful thought to how identifiers (URIs) are minted and maintained. If the URI of a resource changes as your API evolves (e.g. URIs like https://example.com/api/v1/profile/1) it may be worth the investment into adopting other aspects of the available standards, such as content-negotiation, to solve the problem of stable identify for entities and concepts in your organization. Strong, stable identifiers build a foundation to allow data, entities, and concepts to connect across legacy silos.
Once a true level 1 or level 2 API is in place, it becomes a relatively simple incremental effort to allow the business context and semantics to live with the data. JSON-LD as an available media-type (or layered over your existing JSON serialization) provides a capability to add that all-important context to your JSON data. In its simplest form, the context allows the meaning, behavior, and semantics of the data to be defined in such a way that any standards-compliant tool or application can begin to understand the data. It is no longer decontextualized name-value pair, and starts to become knowledge by adopting linked data principles and the standards surrounding the Resource Description Framework (RDF). Other standards in this space, such as the Web Ontology Language, allow more formal definitions of relationships and axiomatic behaviors and enables explainable, deterministic reasoning. At this point standards-based, interoperable data begins to look more and more like actual knowledge that only requires standards-aware software to understand.
 .
.
The final level of the Richardson Maturity Model requires hypermedia, which allows clients to traverse data across multiple legacy silos and discover connections automatically. Increasingly real-time, cross-domain insights are necessary.
Modern work demands knowledge transfer: the ability to apply knowledge to new situations and different domains. Our most fundamental thought processes have changed to accommodate increasing complexity and the need to derive new patterns rather than rely only on familiar ones.
David Epstein, Range
Long-term Thinking Enabling new Capabilities
Long-term and platform thinking aren’t new and we’ve seen the capabilities that can emerge. In the very early 2000s, Jeff Bezos issued one of his now-infamous mandates; this one being his “platform” mandate.
His Big Mandate went something along these lines:
All teams will henceforth expose their data and functionality through service interfaces.
Teams must communicate with each other through these interfaces.
There will be no other form of interprocess communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
It doesn’t matter what technology they use. HTTP, Corba, Pubsub, custom protocols – doesn’t matter. Bezos doesn’t care.
All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
Anyone who doesn’t do this will be fired.
In the early 00s, there was still a lot to learn about service-based architectures, distributed systems, etc.; but ultimately these decisions did catapult the success of the company. At the time this kind of thinking baffled many. “Why would a bookstore need to be an extensible, evolvable platform?!” but this transformation in thinking enabled Amazon to quickly respond to new markets and opportunities. Perhaps the most impactful example was Amazon’s ability to turn the infrastructure they had build for selling and shipping books into a world-class cloud computing platform almost as soon as the market-opportunity was identified. AWS is now the single largest profit-center within Amazon. Despite Amazon commanding around 50% of the US e-commerce market recording around $5,000 in sales every second, their balance-sheet tells the real story; today amazon is a cloud-computing company that dabbles in e-commerce.
This forward thinking also enabled their success in the smart assistant space. When Amazon launched Alexa, the core of the smart assistant’s knowledge stemmed from a knowledgebase called Evi, built by the company “True Knowledge.” True Knowledge built their graph using open RDF knowledge graphs such as DBPedia as well as from vetted human submissions. In this way, Alexa had a factual foundation for answers that language models like ChatGPT have yet to catch up on.
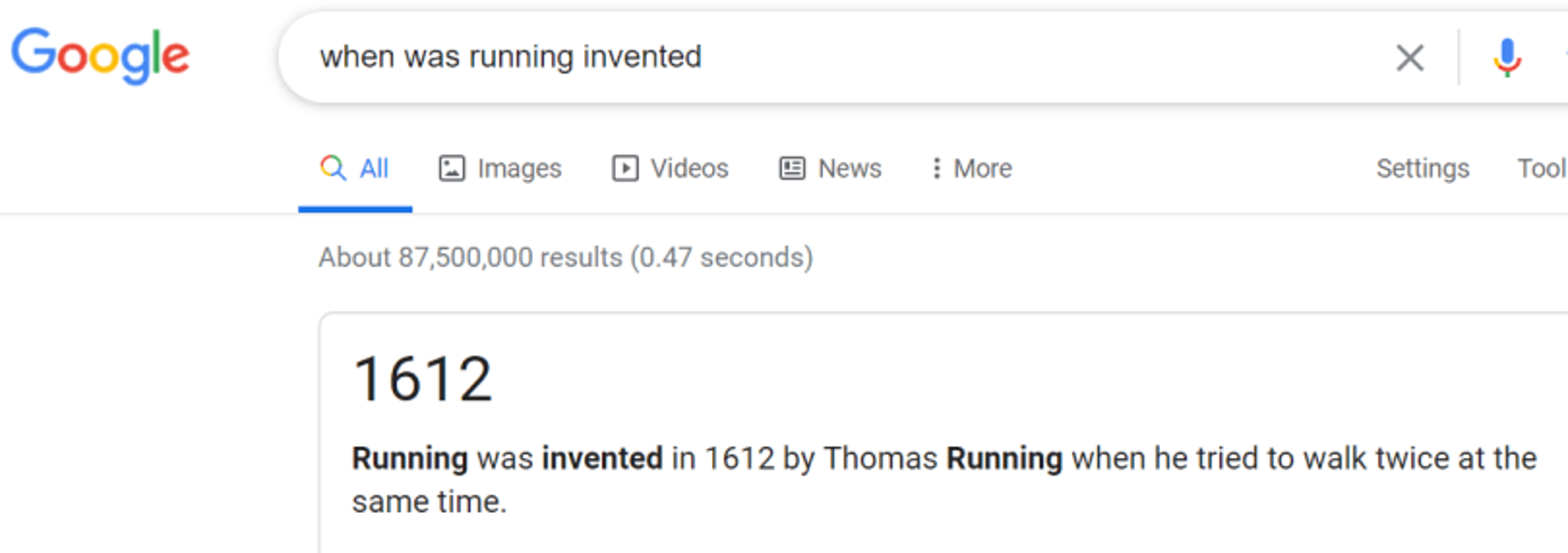
Ask Alexa the same question reveals a factually correct answer.
Having a solid platform foundation, Amazon was able to connect all of their organizational knowledge to Alexa’s knowledge base; product data, reviews, services, music, films, even question and answers. I once asked Alexa to tell me how long cooked bacon can be kept safely in a refrigerator. I was given an answer along with provenance (which is built-in to the linked data standards).

With that provenance I can decide whether to trust the source which is typically not possible with current language models; ChatGPT currently answers questions with a mix of facts and ai “hallucinations.” Again, long-term thinking and linked data standards made this kind of accurate question answering possible years before we began to get excited by large language models.
The greatest enemy of knowledge is not ignorance, it is the illusion of knowledge.
-Stephen Hawking
Tantalizing Possibilities
Almost every organization has complex business questions that can be answered if only organizational knowledge can be broken out of silos and connected in meaningful ways. Thinking beyond narrow point-to-point API integrations and the current application-centric paradigm continues to be a powerful solution. GPT3 is the product of 355 compute-years of training and continues to lack key underlying knowledge.
Structured semantic data like RDF (which can start as a simple incremental improvement to your current APIs) can help future AI language model become more consistently factually correct by providing a standardized way of representing and organizing information. There are many organizational benefits to this kind of long-term thinking in API design, and may unlock the capabilities that we hope tools like ChatGPT will eventually provide. Because RDF (such as JSON-LD) allows us to represent information in a way that is machine-readable. All your organizational data can be better understood by an AI language model allowing it to more easily understand the context and relationships between different pieces of information and enable more informed and accurate responses. Moreover, accurate and explainable reasoning and inference become possible on your organizational data, yielding new insights. Finally, provenance becomes an integral part of the of the data so we may interpret answers with a much more accurate level of confidence.
Conclusion
A well-thought-out REST API may well be the key enabling your data to break free from the numerous silos it’s scattered across. Fully connected, holistic linked data will unlock new insights and deliver them much faster than our current application-centric paradigm allows. When authoring REST APIs, developers often take many shortcuts (URI versioning instead of content-negotiation, avoiding resource modeling, avoiding hypermedia, modeling behavior instead of resources, etc.). Shortcuts are fine if they lead somewhere worth going, but increasingly a data-centric paradigm is becoming necessary to be competitive in the 21st century. The future is Data-Centric. Savvy enterprises are figuring this out and gaining competitive edge, the rest will soon be left behind or marginalized. Thoughtful API design is a good place to start, and the combination of machine learning with structured data and well-defined relationships and semantics might finally deliver on the promise of intelligent agents that are actually intelligent.