The Future is Here (it's Just not Evenly Distributed)

A few weeks ago I wrote an article on how investing in structured, semantic data can help move tools like ChatGPT from the “Trough of disillusionment” to the “plateau of productivity” and create intelligent agents that are actually intelligent. The core was that standardizing on REST Level 1 (or better) and beginning to layer in JSON-LD could provide a more meaningful and factual foundation for generative AI like GPT3 to deliver revolutionary value to organizations.
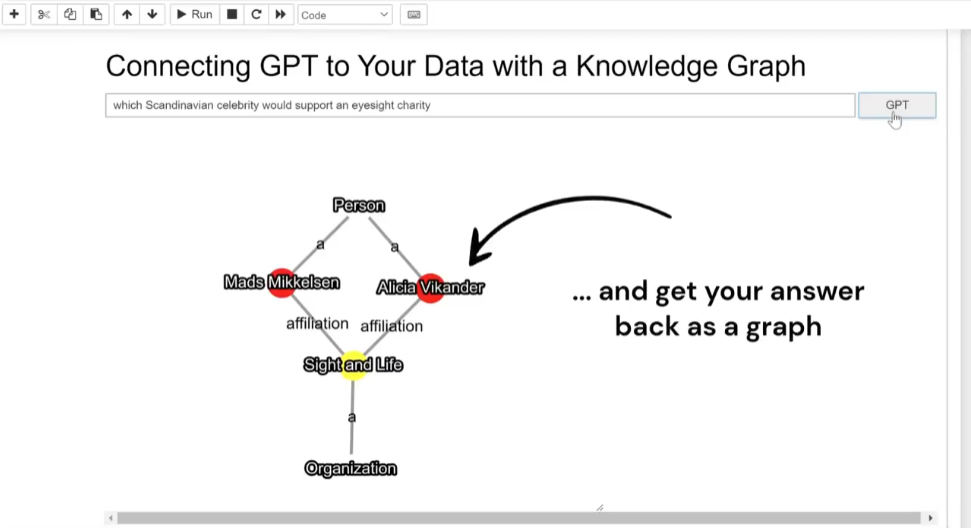
Less that three weeks later, Tony Seale, a Knowledge graph engineer, posted a brief demo video of these ideas in action.
Are you interested in learning how to build a Semantic Layer for your organisation that can communicate with GPT? If so, here’s a valuable tip: use the same data model on which GPT is trained – and suddenly connecting your data to GPT becomes a breeze!
Let’s take a closer look at how this works:
GPT trains on the common crawl, which includes web pages and other sources.
Amazingly, 46% of those web pages now contain islands of JSON-LD that link back to Schema.org.
Because GPT is partly trained on JSON-LD, it can answer back in JSON-LD as well!
To make this work for your organisation, you can create your own schema.org and convert your internal data into JSON-LD too.
Behind the scenes, JSON-LD is structured like a network, and networks can be combined with ease. So your data, and GPT’s answer, merge into a single connected graph.
Whilst the code in this Jupyter notebook is straightforward, the implications of using this free and open architecture are significant. Yes, GPT and its kindred are still in their infancy, but establishing a Semantic Layer takes significant time and effort. That’s why I believe that the time to start working on it is right now!
Source: LinkedIn
Tony also published a useful article on expanding existing ontologies like schema.org for your organization.
Tony’s demo is looking very much like a “fosbury flop” moment for linked data and generative AI.