A few weeks ago I wrote an article on how investing in structured, semantic data can help move tools like ChatGPT from the “Trough of disillusionment” to the “plateau of productivity” and create intelligent agents that are actually intelligent. The core was that standardizing on REST Level 1 (or better) and beginning to layer in JSON-LD could provide a more meaningful and factual foundation for generative AI like GPT3 to deliver revolutionary value to organizations.
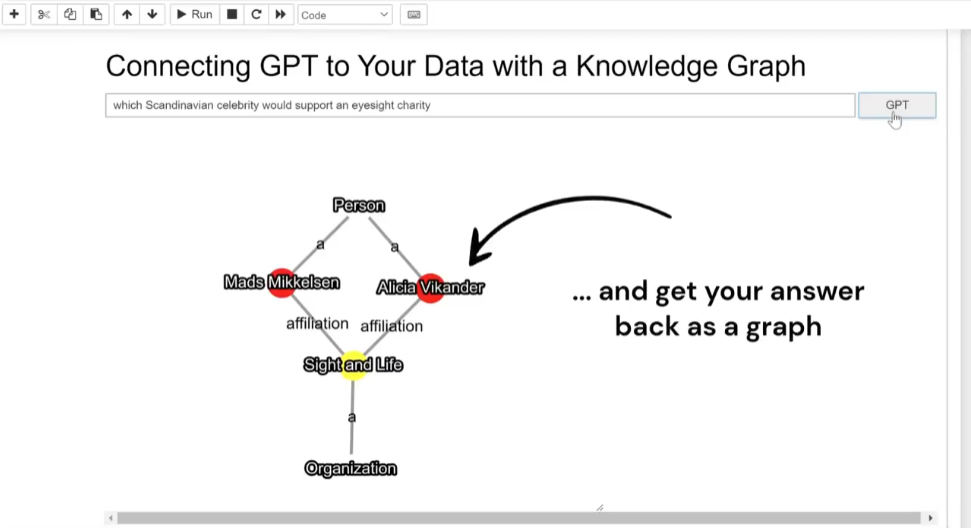
Less that three weeks later, Tony Seale, a Knowledge graph engineer, posted a brief demo video of these ideas in action.
Since ChatGPT became publicly available last November there has been an explosion of interest, articles, blogs, videos, arguments for-and-against; it can be difficult to separate out the hype from the reality. If you haven’t yet played with the public beta, it’s worth taking a look; first impressions are often downright startling.
One of the most impressive capabilities might be ChatGPT’s ability to seemingly answer questions asked in a casual, conversational manner and many hailed this as “the future of search” with Microsoft and Google both scrambling to integrate these capabilities into their search engines. A mind-bogglingly complex language model trained on a web-sized corpus of text boasts stunning capabilities although it doesn’t take long to discover that beneath ChatGPT’s impressive grasp of language there is a serious lack of knowledge. Google’s parent company, Alphabet, recently lost 8% of its market cap–roughly $100b USD–after their live-stream conference demonstrated Bard, their language model, returning incorrect answers.
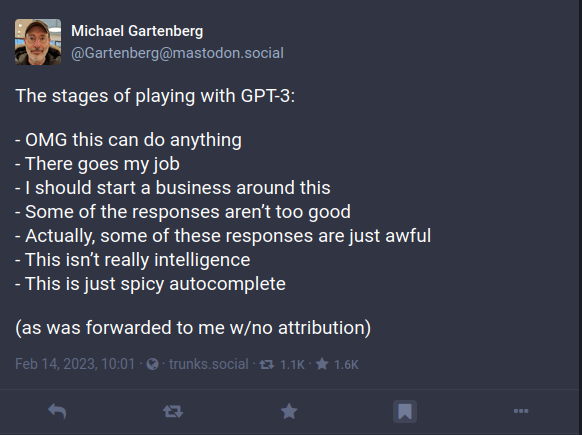
The Mastodon post above summarizes my–and so many other’s–experience. Never in my 20+ years in the industry have I seen a technology move from the “Peak of Inflated Expectations” to the “Trough of Disillusionment” so quickly (see Gartner Hype Cycle). There is something powerful here, especially if it can be integrated with actual knowledge. Forward-thinking organizations are adopting the existing standards and architecture that just might be the key to unlocking the dream that GPT-hype represents. The first step may be as simple as evolving your API strategy.
This is a talk that I have been privileged to see some early drafts of its development. I’ve been eagerly awaiting the finished product. Nimisha Asthagiri joins Scott Davis to lay out the vision of Solid and Pods. It is a delightfully protopian vision, and one that is eminently in reach.
In this talk, Nimisha and Scott explore Tim Berners-Lee’s new vision for the Web – Solid and Pods – where user data is “at the beck and call of the users themselves… a future in which [web] programs work for you”. This is an alternative path where privacy and resiliency are at the heart of our system architectures. A path where the web’s pendulum swings back to decentralization. A path that leads to a fundamentally user-centric tech ecosystem.