Some years ago, I sat in on a conference session hosted by Llewelyn Falco. In one timeboxed exercise, the class collaboratively wrote and iterated over a single line of code. Within about 10 minutes we had come up with several dozen ways to express that single line and, when time ran out, we weren’t slowing down we were speeding up. I left that experience with conviction that there are a near infinite number of ways to write code to implement a set of features. All implementations may provide equivalent functionality, but they don’t necessarily offer the same system capabilities.
In our previous post we discussed how architecture is focused on the capabilities of a system beyond its features and functions. As architects, it’s our job to carefully and mindfully constrain the degrees of freedom on code with the goal of having the desired set of capabilities emerge. But what are the capabilities? In this post we will explore and define various architectural characteristics.
I’ve spent the better part of the past year developing a formal model, process, and distilling a way of thinking about software architecture. The result is an approach I’m calling Tailor Made Architecture. This is the first post in a long series to explore these ideas. If this topic is of interest to you, note that this blog has an atom feed to subscribe to updates. Check out my speaker website for speaking dates where I will be covering this topic. Also, if these ideas resonate and you’d like to participate in an immersive, hands-on, three-day workshop; I’ll be giving the next workshop in Dallas, TX November 13-15. Early-bird discounts are available through October 13th.
2020 was a rough year. Much of my income had come from live performances as a magician, live events as a speaker and trainer, and in-person consulting gigs. By March of 2020, every live event was being dubbed a “super spreader” event, markets were cooling, and enterprises were preparing to “batten down the hatches” in anticipation of unknown societal and financial disruption. My livelihood was in grave jeopardy. My wife and I tightened our belts hoping to ride out the storm but, by the summer, it became clear that this particular storm had an indefinite duration. I eventually accepted a job as a principal software architect at an intriguing startup within the enterprise and quickly rose through the ranks to become their Chief Architect.
As my responsibilities grew, I realized it would be crucial to scale myself and my contributions, so my focus turned to hiring and I had never seen a market like it. Salary expectations had inflated 100%+ since I was in the market. Signing bonuses were being offered at a scale I had never seen before. As it became harder and harder to attract talent, compensation only continued to increase. I won’t lie, I was a little bitter and a little envious. My direct reports I hired were earning substantially more than I. I expressed these feelings to a colleague who asked, “Have you considered looking, yourself?” My response was “It crossed my mind, but I think it would be a bad idea. ‘Those who live by the sword, die by the sword.’” In other words, the tech market looked an awful lot like a bubble. I didn’t know when it would burst, but I knew it would. Companies were responding to the market changes by “warchesting” talent; proactively hiring for roles that didn’t even exist yet. 18 months later came some of the most brutal layoffs I’ve seen since the 2000-2001 era and almost all of those who found themselves swept up in the cuts were downsized through no fault of their own.
I believe another correction is imminent, but this might be a good thing, depending on how we navigate it.
Somewhere in the world there are magicians who are still talking about a magic trick they simply can’t explain… or perhaps they have solved the mystery. The linchpin is a single idea. One fact.
Almost 20 years ago I crossed an ocean to attend my first live magic conference. The headline acts/speakers included Jeff McBride, Eugene Burger, and Darwin Ortiz; all major influences of my work and I couldn’t pass up the opportunity to meet and work with them in person. I went alone and knew nobody attending, although that would change before the convention even began.
In the restaurant on the eve of the convention, I dined solo and mostly people-watched. I watched the retirees who have devoted a portion of their newfound free time to rekindling a childhood hobby. I watched the one or two young kids with their tiger-parent relentlessly molding them in to future Vegas headliners, and I watched the adolescents who spend every waking moment drilling the most difficult sleights and the most elaborate flourishes. There was a whole group of the latter engaged in what could be best described as the legerdemain equivalent of a rap battle, each attempting to one-up the displays of dexterity demonstrated by the last. With nothing to do (and nothing to lose) I approached this group. Minutes later, I left them speechless.
REST is the architecture of the web and the web has seen unprecedented growth and evolution since its inception over 30 years ago. A web of static documents gave rise to the read/write web–the so-called web 2.0. New media types and formats have evolved, protocols have become more powerful and more secure. In short, the web has only grown bigger in scale, more powerful in terms of capabilities, and continues to evolve. The human web is a marvel of software engineering and its longevity is a testament to the vision its founders and architects. Unlike much of the software I use today, I have never opened a web browser to a message that the back-end of the web has undergone a breaking change and I would need to download new software before continuing.
At some point in the first decade of the 21st century the web crossed an inflection point; machine-to-machine API calls eclipsed human traffic on the web. Many of these APIs have been labeled REST APIs despite many–perhaps even most–of these APIs fail to exhibit the qualities elicited by truly following the REST architectural style. Consequently, the machine web consists of a lot of brittle integrations that require countless person-hours to craft and maintain. To be clear, I’m not here to get on my soapbox about how all these sinners are “doing REST wrong”; I really don’t care. Not every API needs to–or should–be a REST API. The REST architectural style is a very specific tool to solve specific problems.
“Some architectural styles are often portrayed as “silver bullet” solutions for all forms of software. However, a good designer should select a style that matches the needs of a particular problem being solved.”
-Dr Roy Fielding
Architectural Styles and the Design of Network Based Architectures
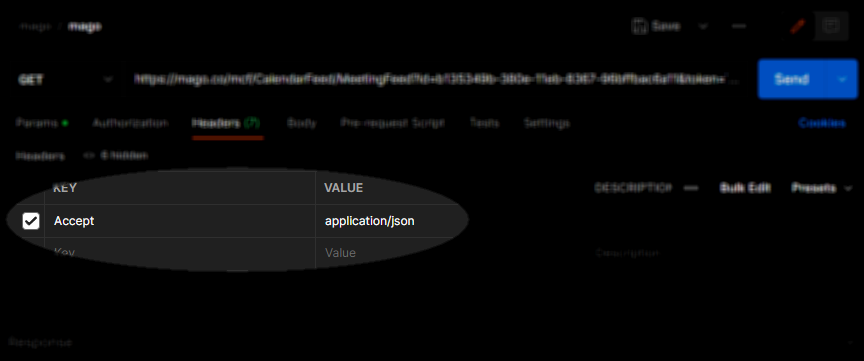
Fundamentally I want to talk about some of the overlooked aspects of this architectural style and how they can be implemented to eliminate problems with versioning, evolution, and flexibility. Today we’re focusing on content negotiation.
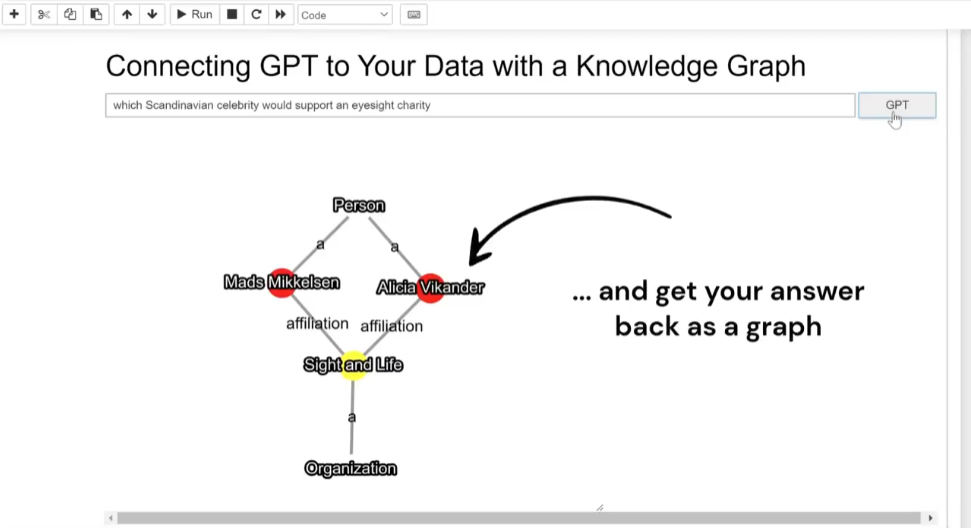
A few weeks ago I wrote an article on how investing in structured, semantic data can help move tools like ChatGPT from the “Trough of disillusionment” to the “plateau of productivity” and create intelligent agents that are actually intelligent. The core was that standardizing on REST Level 1 (or better) and beginning to layer in JSON-LD could provide a more meaningful and factual foundation for generative AI like GPT3 to deliver revolutionary value to organizations.
Less that three weeks later, Tony Seale, a Knowledge graph engineer, posted a brief demo video of these ideas in action.
I spend a lot of time these days thinking about how to turn data into information, and information into knowledge. I work as an independent consultant and help my clients with knowledge management and the architecture and implementation of knowledge systems. I do a lot of R&D in the knowledge graph space and I’ve long dreamt of applying these ideas at personal scale to manage my own knowledge portfolio that allows me to not only capture what I learn, but find it again when I need it.
It turns out, the idea isn’t exactly new, and available technology today makes the dreams of the visionaries who first imagined what technology could do for human cognition are now ready for us to adopt. Applying these to my life and workflow has been transformational! Let me share the tools and techniques I’m currently using.
Since ChatGPT became publicly available last November there has been an explosion of interest, articles, blogs, videos, arguments for-and-against; it can be difficult to separate out the hype from the reality. If you haven’t yet played with the public beta, it’s worth taking a look; first impressions are often downright startling.
One of the most impressive capabilities might be ChatGPT’s ability to seemingly answer questions asked in a casual, conversational manner and many hailed this as “the future of search” with Microsoft and Google both scrambling to integrate these capabilities into their search engines. A mind-bogglingly complex language model trained on a web-sized corpus of text boasts stunning capabilities although it doesn’t take long to discover that beneath ChatGPT’s impressive grasp of language there is a serious lack of knowledge. Google’s parent company, Alphabet, recently lost 8% of its market cap–roughly $100b USD–after their live-stream conference demonstrated Bard, their language model, returning incorrect answers.
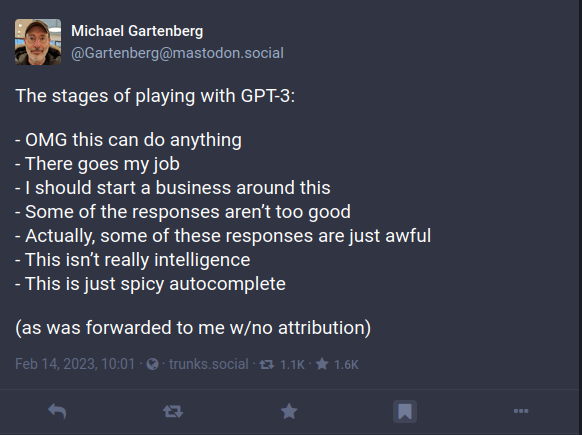
The Mastodon post above summarizes my–and so many other’s–experience. Never in my 20+ years in the industry have I seen a technology move from the “Peak of Inflated Expectations” to the “Trough of Disillusionment” so quickly (see Gartner Hype Cycle). There is something powerful here, especially if it can be integrated with actual knowledge. Forward-thinking organizations are adopting the existing standards and architecture that just might be the key to unlocking the dream that GPT-hype represents. The first step may be as simple as evolving your API strategy.
The 2022 mid-term election was less than a week ago, the dust is still settling and which party controls the chambers of congress remains uncertain. Beyond doing the requisite research necessary to fully complete and submit my ballot, I’ve tried not to follow the day-to-day drama too closely. It’s just not worth my mental health and well-being.
Regardless of the outcome, I’m grateful that election day is now in our societal rear-view-mirror (Except you, Georgia… sorry). The onslaught of political ads has slowed to a trickle as have the heated arguments, the fundraising emails, and the apathetic broadcasting their indifference in quips and memes. I’ve started to reflect on these memes and I am beginning to believe they communicate a deeper truth, and it’s probably not what the poster was intending…
In Part I of this series we discussed the case for reconsidering the humble monolith (with some structural improvements), now we get to the work of actually implementing this architecture pattern in a .Net Core (.Net 6) Web API project. The final base solution will be published on GitHub